
ėŅśõ║═ųŪį¬▒¼╗▒│║¾Ż║╚╦ŅÉ╩Ū╚ń║╬ĮoÖCŲ„╚╦ūó╚ļņ`╗ĻĄ─Ż┐
ĪĪĪĪėŅśõÖCŲ„╚╦į┌┤║═Ē╠°┴╦ę╗ł÷čĒĖĶų«║¾Ż¼╚╦éāī”╚╦ą╬ÖCŲ„╚╦Ą─ĻPūóČ╚ķ_╩╝*Ė▀ØqĪŻ
ĪĪĪĪČ°Š═į┌Ū░╠ņ( 3 į┬ 11 ╚š )Ż¼“ ╚A×ķ╠ņ▓┼╔┘─Ļ ” ų╔Ģ¤Š²╦∙äō┴óĄ─äōśIŲ¾śIųŪį¬ÖCŲ„╚╦░l▓╝┴╦╗∙ė┌ GO-1 Š▀╔ĒųŪ─▄┤¾─Żą═Ą─ųŪį¬ÖCŲ„╚╦ņ`Ž¼ X2 ĪŻ
ĪĪĪĪņ`Ž¼ X2 Įo╬ęéāš╣¼F┴╦╦³ąąū▀ĪóąĪ┼▄Īó“Tūįąą▄ćĪó┴’╗¼░ÕĪó┐pŠĆĪóšZę¶┴─╠ņĪóŪ╬ŲżĄ─ąĪäėū„Ą╚Ą╚╔·äėĄ─ąą×ķĪŻ
ĪĪĪĪ─Ń┐╔─▄Ģ■░l¼FŻ¼ūŅĮ³ā╔─Ļ╚╦ą╬ÖCŲ„╚╦Ą─░lš╣╦┘Č╚ūāĄ├║▄┐ņŻ¼ÖCŲ„╚╦įĮüĒįĮŽ±ę╗éĆėąņ`╗ĻĄ─ “ ╚╦ ”ĪŻ
ĪĪĪĪ─Ū├┤Ż¼ę╗éĆėą╚żĄ─å¢Ņ}üĒ┴╦Ż║╚╦ŅÉ╩Ū╚ń║╬ĮoÖCŲ„╚╦ “ ūó╚ļņ`╗Ļ ” Ą──ž?
ĪĪĪĪ╩ūŽ╚Ż¼╬ęéāꬎ╚├„░ū “ ÖCŲ„╚╦×ķ╩▓├┤▓╗Ģ■╦żĄ╣ ”Ż¼├„░ū┴╦▀@ę╗³cŻ¼─ŃŠ═ų¬Ą└┴╦ÖCŲ„╚╦╩Ū╚ń║╬▀\äėĄ─ĪŻ
ĪĪĪĪ├žįEį┌ė┌Ż║┤¾┼żŠž║═ŲĮ║ŌągĪŻ
ĪĪĪĪÖCŲ„╚╦Ą─▀\äėŻ¼ūŅ║åå╬Ą─ĘĮ╩ĮŻ¼┐╔ęįĘųĮŌ×ķ▒Š¾w▀\äė║═ų½¾w▀\äėĪŻ
ĪĪĪĪų½¾w▀\äė░³└©╔Ē¾wĖ„éĆĻP╣ØĄ─ą²▐DĪóų½¾wĄ─╔ņ┐sĄ╚Ż¼▀@Š═ŽÓ«öė┌īóų½¾w▀\äėĘųĮŌ×ķ┴╦ą²▐D▀\äė║═ų▒ŠĆ▀\äėĪŻ
![]()
ĪĪĪĪČ°ų▒ŠĆ▀\äėŻ¼╩Ū┐╔ęį═©▀^ą²▐D▀\äėüĒ▒Ē▀_Ą─Ż¼▒╚╚ńöQ┬▌ĮzŻ¼Š═╩Ū═©▀^ą²▐D▀\äė▀_│╔┴╦ų▒ŠĆ▀\äėĪŻ
![]()
ĪĪĪĪ╦∙ęįŻ¼─Ń┐╔ęį░čÖCŲ„╚╦ę╗ŪąĄ─▀\äėČ╝┐┤ū„╩Ūę╗ŽĄ┴ąą²▐D▀\äėĮM│╔Ą─Ż¼Č°▀_│╔▀@ą®ą²▐D▀\äėŻ¼═©▀^ļŖÖCŠ═┐╔ęįīŹ¼FĪŻ
![]()
ĪĪĪĪČ°▀@ų«ųąŻ¼ėųėąę╗éĆ▒╚▌^ĻPµIĄ─³cŻ║į┌ÖCąĄ▒█Ą─╣żū„╩╣ė├ųąŻ¼═©│ŻąĶę¬ėąūŃē“┤¾Ą─┼żŠžŻ¼ė╚Ųõī”╚╦ą╬ÖCŲ„╚╦üĒšfŻ¼┤¾┼żŠžĄ─ęŌ┴x╠žäeÅVĘ║ĪŻ
ĪĪĪĪėą┴╦┤¾┼żŠžŻ¼ÖCąĄ▒█┐╔ęį╩®╝ėĖ³ÅŖĄ─┴”Ż¼ė├ė┌┼eŲųž╬’Ż¼ę▓─▄į┌│ą▌dųž╬’Ģr▒Ż│ųĘĆČ©Ż¼┐╣Ė╔ö_─▄┴”╝ėÅŖŻ¼▒╚╚ń░ß▀\ÖCŲ„╚╦ĪŻ
ĪĪĪĪė╔ė┌▐D╦┘ĮĄĄ═( ╣”┬╩=┼żŠž*▐D╦┘Ż¼╣”┬╩ŽÓ═¼Ģr┼żŠžįĮ┤¾▐D╦┘įĮĄ═ )Ż¼┐╔ęįŠ½£╩┐žųŲą²▐DĮŪŻ¼Å─Č°▀MąąŠ½├▄▓┘ū„Ż¼═¼Ģr─▄ē“┐╦Ę■ĮM┐ŚūĶ┴”Ż¼▒╚╚ńŠ½├▄╩ųągÖCŲ„╚╦ĪŻ
ĪĪĪĪČ°ūŅųžę¬Ą─ę╗³c╩ŪŻ¼ī”ė┌ąąū▀Īó┼└Ų┬╗“┐ńįĮšŽĄKŻ¼┤¾┼żŠžęŌ╬Čų°ÖCŲ„╚╦─▄ē“┐╦Ę■Ąž├µ─”▓┴Īóųž┴”║═Ųõ╦¹ūĶ┴”Ż¼┤_▒ŻĘĆČ©Ą─▀\äėĪŻ
ĪĪĪĪėą┴╦┤¾┼żŠž▀@éĆŽ╚øQŚl╝■Ż¼ĮėŽ┬üĒŠ═╩ŪŲĮ║ŌągĪŻ
ĪĪĪĪ▒Š¾w▀\äė┐╔ęį└ĒĮŌ×ķ╩ŪÖCŲ„╚╦═©▀^ų½¾w▀\äė┼cŁhŠ│Į╗╗ź( ▒╚╚ń─”▓┴Īó═Ų┴”Ą╚ )īŹ¼FĄ─┘|ą─Ą─ŲĮęŲĪóą²▐D▀\äėŻ¼Å─Č°▀_ĄĮ░³└©ąąū▀Īó┼▄äė╔§ų┴║¾┐šĘŁĄ╚─┐Ą─ĪŻ
ĪĪĪĪŽļ║åå╬└ĒĮŌ▀@éĆĖ┼─ŅŻ¼─Ń┐╔ęį¼Fį┌šŠŲüĒū▀Äū▓ĮŻ¼▓óŪęų╗ĻPūóūį╝║Ą─Ųõųąę╗ų╗─_Ż¼▒╚╚ńėę─_Ż¼Ģ■░l¼F▀^│╠╩Ū▀@śėĄ─Ż║
ĪĪĪĪėę─_▀~│÷▓ó┬õį┌Ū░ĘĮ;
ĪĪĪĪ╔Ē¾wć·└@ų°Ū░ĘĮ┬õ─_³cŻ¼Ž“Ū░ “ ╦”│÷╚ź ”;
ĪĪĪĪų▒ĄĮ╔Ē¾w▒╗ “ ╦” ” Ą─┐ņ╩¦╚źŲĮ║Ō┴╦Ż¼ū¾─_═╗╚╗│÷¼FŻ¼Ä═─Ńō╬ūĪ╔Ē¾wĪŻ
ĪĪĪĪ▀@éĆ▀^│╠Ż¼ŲõīŹ║▄Ž±ę╗éĆĄ╣┴óĄ─ńŖö[Ž“Ū░ĘĮę╗ “ ╦” ” ę╗ “ ╦” ” Ąžö[äėĪŻ
![]()
ĪĪĪĪø]ÕeŻ¼į┌ÖCŲ„╚╦äė┴”īWųąŻ¼┤_īŹę▓Ģ■īó╚╦ą╬ÖCŲ„╚╦║å╗»×ķę╗éĆŠĆąįĄ╣┴óö[─Żą═Ż¼╝┤ų°├¹Ą─ LIPM ─Żą═Ż¼╦³─▄║▄║├ĄžūźūĪ╚╦ą╬ÖCŲ„╚╦▀\äėĄ─╗∙▒ŠęÄ┬╔ĪŻ

ĪĪĪĪį┌▀@éĆ─Żą═ųąŻ¼╝┘įOÖCŲ„╚╦╦∙ėąųž┴┐╝»ųąį┌ę╗éĆ┘|ą─³c╔ŽŻ¼ė├¤o┘|┴┐Ą─ŚUō╬į┌Ąž├µ╔ŽŻ¼į┌ąąū▀Ģr▒Ż│ų┘|ą─Ė▀Č╚▓╗ūāĪŻ
ĪĪĪĪ▀@ĢrŻ¼į┌Ąž├µ╔Ž┤µį┌ę╗éĆ³cŻ¼ć·└@▀@éĆ³c┐╔ęįėŗ╦Ń│÷╦∙ėą╦«ŲĮĘĮŽ“Ą─┴”Šžų«║═×ķ┴ŃŻ¼ĘQų«×ķ┴Ń┴”Šž³cŻ¼╝┤ ZMP( Zero Moment Point )ĪŻ
ĪĪĪĪ┴Ń┴”Šž³cšf├„ÖCŲ„╚╦▓╗Ģ■ć·└@▀@éĆ³c╔ŽĄ─ŲĮąąė┌▀@éĆŲĮ├µĄ─▌Są²▐DĪŻ( ┐╔ęį└ĒĮŌ×ķ▓╗Ģ■ą²▐Dų°╦żĄ╣į┌Ąž )
ĪĪĪĪ╚ń╣¹─ŃėXĄ├▀@śė└ĒĮŌ╠½│ķŽ¾Ż¼─Ń┐╔ęį┐┤┐┤╗©╗¼▀\äėåTŻ¼╦¹éāĄ─╔Ē¾w╚ń╣¹ć·└@╔Ē¾wžQų▒ĘĮŽ“Ą─┴”Šžų«║═╩Ū▓╗×ķ┴ŃĄ─Ż¼─Ū├┤ŲõŠ═Ģ■ķ_╩╝ą²▐DĪŻ
![]()
ĪĪĪĪ┤¾Ė┼└ĒĮŌ┴╦╩▓├┤╩Ū ZMP ų«║¾Ż¼╬ę┐╔ęįĖµįV─Ńę╗éĆ╣½╩ĮŻ¼▀@éĆ╣½╩ĮŠ═╩ŪÖCŲ„╚╦ąąū▀ĢrĄ─ “ Ą╣┴óö[ ” ╣½╩ĮŻ║
![]()
ĪĪĪĪ─Ń▓╗ąĶę¬└ĒĮŌ▀@éĆ¢|╬„Ż¼─Ńų╗ąĶę¬ų¬Ą└╬ęéā░č “ ąąū▀” ▀@╝■╩┬▐D╗»│╔┴╦ę╗éĆĘĮ│╠Ż¼Žļę¬ū▀║├┬ĘŻ¼╬ęéāę¬ū÷Ą─Š═╩ŪĮŌĘĮ│╠ĪŻ
ĪĪĪĪ▓╗▀^Ż¼LIPM ─Żą═║▄║åå╬Ż¼╦¹╩Ūę╗éĆ▒╚▌^└ĒŽļĄ──Żą═Ż¼╔·╗Ņųą║▄ļyėą═Ļ╚½Į³╦Ųė┌▀@éĆ║åå╬─Żą═Ą─▀\äėĪŻ▒╚╚ńÖCŲ„╚╦Ą─╦┘Č╚ūā╗»▀^┤¾Ż¼┘|ą─ūā╗»▀^┤¾( ▒╚╚ńüy▒─üy╠°╗“╠°╬Ķ )Ż¼╗“┘|ą─▓╗ĘĆČ©( ▒╚╚ńūź╬š╬’ŲĘ╗“╔Ē╔ŽÆņų°▓╗ĘĆČ©Ą─Ų„╝■ )Ż¼Č╝Ģ■ūīīŹļHŪķør├ōļx─Żą═Ż¼Ä¦üĒ║▄┤¾Ą─ŲĮ║ŌļyŅ}ĪŻ
ĪĪĪĪ╦∙ęįŻ¼─ŃĢ■┐┤ĄĮįńŲ┌Ą─ÖCŲ„╚╦Č╝ė├ąĪ╦ķ▓Įąąū▀Ż¼▀@śė┐╔ęį▒Ż│ųĖ³╝ėŲĮĘĆĄ─╦┘Č╚ęį╝░Ė³ąĪĄ─╝ė╦┘Č╚Ż¼Å─Č°Ų½ęŲ│╠Č╚ąĪŻ¼Ė³╚▌ęū▒Ż│ųŲĮ║ŌĪŻČ°ÖCŲ„╚╦ė├ÅØŪ·Ą─Žź╔wąąū▀Ż¼┐╔ęįūī┘|ą─▒Ż│ųį┌ŽÓ═¼Ė▀Č╚Ż¼Ė³╝ė▀m┼õ▀@éĆśO║åĄ──Żą═Ż¼ę▓Š═▒▄├Ō┴╦Ė³ČÓÅ═ļsę“╦žĄ─ę²╚ļĪŻ
ĪĪĪĪÅ─ęį╔ŽėæšōųąŻ¼╬ęéāę▓┐╔ęįī”▀\äėėąę╗éĆą┬Ą─šJūRĮŪČ╚ĪŻ
ĪĪĪĪąąū▀▓ó▓╗╩ŪĢr┐╠▒Ż│ųų°ŲĮ║ŌĀŅæBŻ¼Č°╩Ū▓╗öÓ╠Äė┌ę╗ų╗─_ųŲįņ╩¦║ŌČ°┴Ēę╗ų╗─_Ž¹│²╩¦║ŌĄ─äėæBŲĮ║Ō▀^│╠Ż¼Å─Č°═ŲäėÖCŲ„╚╦Ū░▀MĪŻ
ĪĪĪĪLIPM ─Żą═ėæšōĄ─╩Ūī”ÖCŲ„╚╦▀\äėĄ─Ž▐ųŲę“╦žŻ¼Ą½į┌īŹļH▀\äėųąŻ¼ÖCŲ„╚╦«ö╚╗▓ó▓╗╩Ū░┤ššĘĮ│╠═Ļ╚½▒╗äėĄžąąū▀Ą─Ż¼Č°╩ŪŽ╚ęÄäØę╗éĆģó┐╝ ZMP Ą─┬ĘŠĆŻ¼į┘░┤ššėŗ╦ŃĄ─┘|ą─╬╗ų├║═╝ė╦┘Č╚īŹļH╚źąąū▀Ż¼┤_▒Żį┌▀@▀^│╠ųąŻ¼īŹļHĄ─ ZMP ┼cģó┐╝ ZMP ▒M┐╔─▄ųž║ŽŻ¼Å─Č°▒Ż│ųŲĮ║ŌĪŻ
![]()
ĪĪĪĪČ°ÖCŲ„╚╦ę¬į┌╚╬ęŌĢr┐╠▒Ż│ųŲĮ║ŌŻ¼Š═ąĶę¬▒Ż│ų ZMP ³c( ╔ŽłDÖCŲ„╚╦╔Ē¾wŽ┬ĘĮś╦ėøĄ─ę╗éĆ³c )╬╗ė┌ų¦ō╬ČÓ▀ģą╬ā╚ĪŻų¦ō╬ČÓ▀ģą╬┐╔ęį║åå╬└ĒĮŌ×ķ╔ŽłDÖCŲ„╚╦Ą─Įėė|Ąž├µĄ──_ć·│╔Ą─ČÓ▀ģą╬ĪŻ
ĪĪĪĪ▀@╠½Å═ļs┴╦Ż¼┐┤ĄĮ▀@└’─Ń┐╔─▄┐ņę¬Ģ×┴╦Ż¼▓╗▀^ø]ĻPŽĄŻ¼ÖCŲ„ūį╝║ę▓▓╗└ĒĮŌŻ¼╦∙ęįŻ¼ūó╚ļņ`╗ĻĄ─▓Į¾Eķ_╩╝┴╦Ż║╬ęéāįćłDūīÖCŲ„ūį╝║īWĢ■└ĒĮŌ╚ń║╬╚źū▀┬ĘĪóū÷äėū„ĪŻ
ĪĪĪĪąąū▀Īó▒╝┼▄Ą╚╗∙▒ŠĄ─▀\äėąą×ķę╗░Ń╩Ū═©▀^ĮøĄõ AI ╦ŃĘ©ÅŖ╗»īW┴Ģė¢ŠÜĄ├ĄĮĄ─Ż¼įń─Ļę╗ų▒▓╗ė├ AI ╝╝ągĪó│╔▒ŠĮĄ▓╗Ž┬üĒĄ─▓©╩┐ŅDäė┴”¼Fį┌ę▓į┌ė├ÅŖ╗»īW┴ĢüĒė¢ŠÜ Spot ÖCŲ„╚╦║═ Atlas ÖCŲ„╚╦ĪŻ
ĪĪĪĪÅŖ╗»īW┴ĢĄ─įŁ└Ē┤¾ų┬╩ŪŻ¼▒╚╚ńÖCŲ„╚╦į┌ąąū▀ĢrŻ¼╚ń╣¹▓╔ė├┴╦š²┤_Ą─▓ĮĘź╗“š▀ø]ėą╦żĄ╣Ż¼Š═╠ß╣®¬ääŅŻ¼╚ń╣¹▓╔ė├┴╦Õeš`Ą─▓ĮĘź╗“š▀╦żĄ╣┴╦Ż¼Š═▀Mąąæ═┴PĪŻ▀@į┌ė╬æ“Ą─šZŠ│ųą║▄╚▌ęū└ĒĮŌŻ¼│įČ╣╚╦│įĄĮČ╣ūė┴╦Š═ėą¬ääŅŻ¼▒╗ė─ņ`ūźūĪ┴╦Š═ėąæ═┴PĪŻ
![]()
ĪĪĪĪ═¼śėŻ¼ÖCŲ„╚╦Įė╩šĄĮ¬ääŅą┼╠¢Ż¼Š═Ģ■ÅŖ╗»«öŪ░Ą─ąą×ķŻ¼Įė╩šĄĮæ═┴Pą┼╠¢Ż¼Š═Ģ■╚§╗»«öŪ░ąą×ķĪŻ
ĪĪĪĪÅŖ╗»īW┴Ģ╗∙▒Š╩ŪÖCŲ„╚╦īW┴ĢĄ─Ąūīė┼õų├┴╦Ż¼Ą½╦³ę▓ėąĘŪ│Ż┤¾Ą─╚▒³cĪŻ
ĪĪĪĪÖCŲ„╚╦ėųėą╠½ČÓĄ─ĘĮ╩Į╗“äėū„üĒ═Ļ│╔═¼ę╗éĆ╚╬䚯¼ę▓Š═╩Ūäėū„┐šķg╠½┤¾ĪŻ
ĪĪĪĪ▀@Š═Ž±╩Ūį┌ę╗éĆĘŪ│Ż²ŗ┤¾ĄžłDĄ─ķ_Ę┼╩Įė╬æ“ųąŻ¼ø]ėą╠žČ©Ą─╚╬äšųĖę²Ż¼ų╗─▄┐┐ę╗³cę╗³cĄ─├■╦„üĒ½@╚ĪĘ┤üŻ¼▀@śė╣╠╚╗ėąĘŪ│Ż┤¾Ą─äōą┬ūįė╔Č╚Ż¼▒╚╚ńAlphaGo─▄ē“▓╔ė├╚╦ŅÉęŌŽļ▓╗ĄĮĄ─ĘĮ╩ĮüĒū▀ŲÕĪŻ
ĪĪĪĪ╦¹Ą─▒ūČ╦╩Ū┘Yį┤Ž¹║─╠žäe┤¾Ż¼Č°Ūęę▓ėą┐╔─▄ūīÖCŲ„╚╦ė├ęŌŽļ▓╗ĄĮĄ─ĘĮ╩Į½@╚Ī¬ääŅĪŻ
ĪĪĪĪ▒╚╚ńņ`Ž¼ X2 ÖCŲ„╚╦ė¢ŠÜĢrĢ■ėą “ │ķŽ¾ ” Ą─ąąū▀ĘĮ╩ĮŻ¼▀@ą®ĘĮ╩Į─▄ē“ØMūŃ “ Ū░▀M ” ▀@ę╗─┐ś╦Ż¼Ą½’@╚╗▓╗╩Ū╬ęéāŽļꬥ─ąą×ķŻ¼▀@ĘN¼FŽ¾═©│Ż▒╗ĘQ×ķ “ reward hacking ”ĪŻ
ĪĪĪĪ╚ńĮ±Ż¼╚╦ą╬ÖCŲ„╚╦ėąę╗éĆ░lš╣┌ģä▌Š═╩Ūūįė╔Č╚įĮüĒįĮ┤¾Ż¼▒╚╚ń╩ųųĖöĄ┴┐║═ĻP╣ØöĄ┴┐įĮüĒįĮČÓŻ¼ī”ė┌Š▀ėąįĮüĒįĮČÓūįė╔Č╚Ą─╚╦ą╬ÖCŲ„╚╦Ż¼├┐éĆĀŅæBŽ┬┐╔ęį▓╔╚ĪĄ─äėū„öĄ┴┐│╩ųĖöĄ╝ēį÷ķLĪŻ
ĪĪĪĪŽ┬łD╦∙╩ŠĄ─║▄╣┼įńĄ─▒Š╠’ÖCŲ„╚╦ėą 30 éĆūįė╔Č╚ ( DOF )Ż¼├┐éĆūįė╔Č╚Č╝ąĶę¬į┌├┐éĆĢr┐╠░l│÷├³┴ŅĪŻ╝┤╩╣├┐éĆ DOF Ą─├³┴Ņų╗ėą╚²éĆ┐╔─▄Ą─ųĄ( └²╚ńŪ░▀MĪó║¾═╦║═¤o )Ż¼Ą½į┌├┐éĆĀŅæBŽ┬Č╝┐╔ęį▓╔╚Ī 3^30 ĘN▓╗═¼äėū„Ą─ĮM║ŽĪŻ
![]()
ĪĪĪĪ▀@Š═ūīÖCŲ„╚╦▓╔ė├Õeš`ąą×ķĄ─Ė┼┬╩( ╝┤▒Ń─▄ē“▀_ĄĮŽÓ═¼─┐ś╦ )śO┤¾ĪŻ
ĪĪĪĪė┌╩ŪŻ¼╚╦éā╠ß│÷┴╦ “ ─ŻĘ┬īW┴Ģ ” ▀@ę╗Ė┼─ŅüĒÅøča▓╗ūŃŻ¼╦³ūīÖCŲ„╚╦═©▀^ė^▓ņŲõ╦³ÖCŲ„╚╦╗“╚╦ŅÉĄ─äėū„üĒīW┴ĢŻ¼▀@śėŠ═░čäėū„ĄĮ╚╬äš─┐ś╦Ą─┬ĘÅĮČ╝ęÄäØ║├┴╦Ż¼╔§ų┴▓╗ąĶę¬įOų├¬ääŅĪŻ

ĪĪĪĪłDį┤Ż║https://human2robot.github.io/
ĪĪĪĪ─ŻĘ┬īW┴ĢśO┤¾┐sąĪ┴╦äėū„┐šķgŻ¼▓ó▒▄├Ō┴╦¤oą¦Ą─╠Į╦„ĪŻ
ĪĪĪĪ▀@ŽÓ«öė┌░čįŁüĒķ_Ę┼ąįśO┤¾Ą─ÅŖ╗»īW┴ĢŻ¼Ė─įņ│╔┴╦ę╗éĆŅÉ╦ŲłDŽ±ūRäeĄ─▒OČĮīW┴Ģ╦ŃĘ©ĪŻ╔§ų┴╠°╬ĶĪó┤“Ų╣┼ęŪ“Ą╚Ė³╝ėŠ▀éõ╚╦ŅÉ╠žąįĄ─ąą×ķę▓╩Ū═©▀^─ŻĘ┬īW┴ĢīŹ¼FĄ─ĪŻ
ĪĪĪĪĄ½Ż¼─ŻĘ┬īW┴Ģę▓Ģ■ė÷ĄĮę╗éĆ║╦ą─å¢Ņ}ĪŻ
ĪĪĪĪAgent į┌īW┴ĢĢrų▒Įė─ŻĘ┬┴╦īŻ╝ę╠ß╣®Ą─äėū„Ż¼Č°▓╗╣▄Į╗╗źĄ─ūŅĮKĮY╣¹Ż¼Š═║├Ž±ę╗éĆīW═Įų╗░┤ššÄ¤ĖĄ╠ß╣®Ą─║åå╬ł÷Š░üĒķ_▄ćŻ¼ę╗░Ńų╗ąĶę¬░┤▓┐Š═░ÓĄž▓┘ū„Š═ąąŻ¼ę╗Ą®į┌¼FīŹųąīŹ▓┘Ż¼Š═╚▌ęū│÷ÕeĪŻ
ĪĪĪĪ╚╦éāę▓ćLįć┴╦▓╗═¼Ą─ĮŌøQĘĮĘ©Ż¼▒╚╚ńŻ¼Į╗╗ź╩Į─ŻĘ┬īW┴ĢĪŻAgentį┌£yįćĢr╚ń╣¹│÷Õe┴╦╗“ė÷ĄĮ┴╦īW┴ĢĘČć·ęį═ŌĄ─ł÷Š░Ż¼Ģ■Ž“╚╦ŅÉīŻ╝ęįāå¢Ż¼╚╗║¾╚╦ŅÉīŻ╝ę╩╣ė├£╩┤_Ą─äėū„ųžą┬ś╦ėø Agent ╩š╝»Ą─öĄō■ĪŻ
ĪĪĪĪĄĮ▀@└’Ż¼─Ńæ¬įō─▄├„░ūŻ¼öĄō■Ż¼╩Ūę╗éĆĘŪ│Żųžę¬Ą─³cĪŻ
ĪĪĪĪÅ─▀^╚źę╗─ĻĄ─▀Mš╣┐┤üĒŻ¼ųŪį¬ÖCŲ„╚╦┐╔─▄Š═╩ŪŽŻ═¹ė├─ŻĘ┬īW┴ĢĮY║Ž│¼┤¾ęÄ─ŻöĄō■░č “ ═©ė├ ” ę╗┬Ęū▀ĄĮ║┌ĪŻ
ĪĪĪĪ╩ūŽ╚╩Ūū÷┴╦ AgiBot WorldŻ¼ę╗éĆ░┘╚f╝ēĄ─ÖCŲ„╚╦šµÖCīŹ▓┘öĄō■╝»Ż¼ų„┤“īŻśIąįĪŻ
ĪĪĪĪ╦³░³║¼Ą─╗∙ĄAäėū„ČÓŻ¼▒╚╚ńūź╚ĪĪóĘ┼ų├Īó═ŲĪó└ŁĄ╚╗∙ĄA▓┘ū„Ż¼ęį╝░öć░ĶĪóš█»BĪóņ┘ĀCĄ╚Å═ļsäėū„;ł÷Š░ėųČÓśėŻ¼Ė▓╔w╝ęŠėĪó▓═’ŗĪó╣żśIĪó╔╠│¼Īó▐k╣½;öĄō■─ŻæBžSĖ╗Ż¼360 Č╚¤o╦└ĮŪęĢėXĖąų¬Ż¼ęį╝░┴∙ŠS┴”é„ĖąŲ„║═Ė▀Š½Č╚ė|ėXé„ĖąŲ„Ą─öĄō■Ż¼║¾š▀ī”ė┌Š½£╩▓┘┐žĄ─ė¢ŠÜ▒ž▓╗┐╔╔┘ĪŻ
ĪĪĪĪį┌┐╔ęĢ╗»ęĢłDŽ┬Ż¼┐╔ęį┐┤ĄĮÖCŲ„╚╦╦∙Ėąų¬Ą─öĄō■ą╬æBŻ¼Ųõųą░³║¼┴╦├┐Ģr├┐┐╠Ą─ 360 Č╚ RGB łDŽ±Īó╔ŅČ╚łDĪóęį╝░┤╦ĢrĄ─äėū„ĀŅæBĪŻ

ĪĪĪĪ╚╗║¾╦¹éā▀Ćū÷┴╦ AgiBot Digital WorldŻ¼Ė³┤¾ęÄ─ŻĄ─ÖCŲ„╚╦╠ōöMĘ┬šµ┐“╝▄║═ķ_į┤öĄō■╝»Ż¼ų„┤“ļSÖCąįĪŻ
ĪĪĪĪ╩ūŽ╚╩Ū▒Ż│ų┴╦ĮėĮ³šµÖCöĄō■Ą──ŻæBžSĖ╗ąįŻ¼╚╗║¾ėų─▄į┌═¼śėĄ─╚╬䚎┬Ż¼╔·│╔┤¾┴┐Ą─ļSÖCę“╦žĪŻ

ĪĪĪĪ╔·│╔▓╗ŽÓĻPĄ─ę“╦žŻ¼─┐Ą─╩Ū×ķ┴╦ūī╔±ĮøŠWĮjų¬Ą└Ż¼į┌ę╗éĆ╚╬䚎┬Ż¼──ą®╩ŪŽÓĻPĄ─Ż¼──ą®╩Ū▓╗ŽÓĻPĄ─Ż¼«ģŠ╣╔±ĮøŠWĮj▀^ė┌┤Ó╚§├¶ĖąŻ¼ÄūéĆęŌ┴Žų«═ŌĄ─Ž±╦žŠ═─▄ūī╦³┤¾│įę╗¾@Ż¼═³┴╦ūį╝║╩ŪšlĪóüĒūį──└’Īóę¬╚ź──ā║ĪŻ
ĪĪĪĪÖCŲ„╚╦╚ń╣¹ø]ėąĮėė|ĄĮ▀@ą®ļSÖCę“╦žŻ¼ę▓Š═╚▒╔┘┴╦ “ ʱȩ ” Ą──▄┴”Ż¼╝ė╚ļļSÖCę“╦ž─▄║▄║├ĮŌøQ▀@éĆå¢Ņ}ĪŻ
ĪĪĪĪų╗╩Ūį┘ČÓĄ─ļSÖC╗»ę▓▓╗─▄Åø║Ž╠ōöM║═¼FīŹĄ─▓ŅŠÓ( sim2real gap )Ż¼¼FīŹĄ─Å═ļsąį▀h│¼╬ęéāŽļŽ¾ĪŻ
ĪĪĪĪį§├┤Åø║Ž▀@ĘN▓ŅŠÓ─ž?ĻPµIį┌ė┌ų¬ūR╣▓ŽĒĪŻ
ĪĪĪĪ╔±ĮøŠWĮjĄ─ųąķgīė─▄īW┴ĢĄĮę╗éĆ▒Ēš„┐šķgŻ¼▒Ēš„┐šķgļ[║¼┴╦ė^▓ņ¼FŽ¾▒│║¾Ą─Ąūīėų¬ūRŻ¼ļm╚╗▀Ć▓╗─▄═Ļ╚½└ĒĮŌ╦³Ż¼Ą½īó▀@ę╗īė▀Mąą╣▓ŽĒŻ¼Š═┐╔ęįīóŲõųąĄ─ų¬ūR╝╝─▄▀Mąą▀węŲŻ¼▀@ę╗³c╩Ūį┌╔ŅČ╚īW┴ĢĄņ╗∙š▀Yoshua Bengio║▄įńŲ┌Ą─šō╬─ “ Representation Learning: A Review and New Perspectives ” ųąŠ═╠ß│÷üĒĄ─╔Ņ┐╠Č┤▓ņĪŻ

ĪĪĪĪ▒╚╚ńį┌▀@ĒŚčąŠ┐ųąŻ¼ÖCŲ„╚╦Š═īW┴Ģ┴╦ę╗ĘNų¬ūR╣▓ŽĒĄ─ĘĮ╩ĮĪŻ
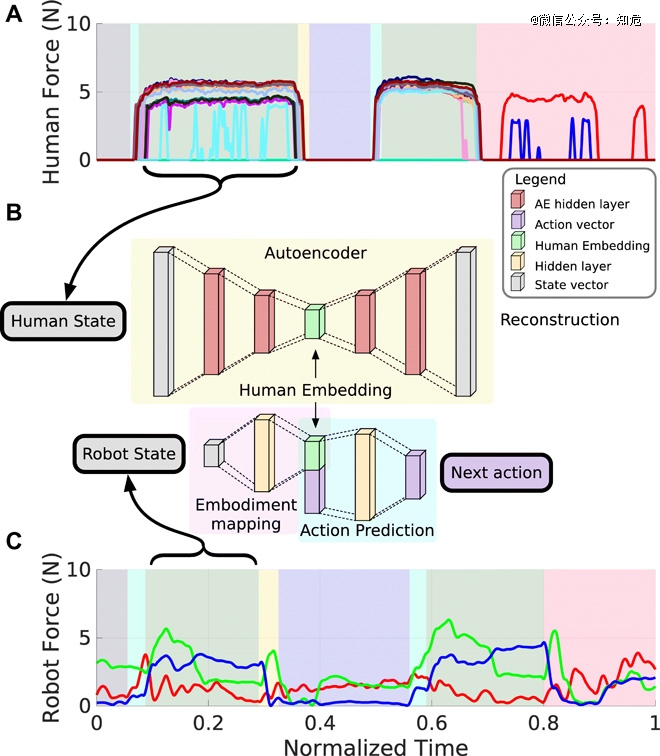
ĪĪĪĪłDį┤Ż║https://www.science.org/doi/10.1126/scirobotics.aay4663
ĪĪĪĪį┌ķ_╦ÄŲ┐╚╬äšųąŻ¼ÖCŲ„╚╦Å─╚╦ŅÉč▌╩ŠųąīW┴Ģį§├┤öQŲ┐╔wĪŻ
ĪĪĪĪ╚╦ŅÉäėū„Ą─ė|ėXöĄō■Ż¼═©▀^╔±ĮøŠWĮj▐D╗»×ķ▒Ēš„ AŻ¼A į┘▐D╗»×ķ╚ń║╬öQŲ┐╔wĄ─Ė▀╝ēøQ▓▀ĪŻ
ĪĪĪĪī”ė┌▓╗═¼ŅÉą═Ą─ÖCŲ„╚╦äėū„Ą─ė|ėXöĄō■Ż¼ät═©▀^┴Ēę╗éĆ╔±ĮøŠWĮjŻ¼ė│╔õĄĮ AŻ¼▀@ŽÓ«öė┌╩Ūę╗éĆĄ═╝ēäėū„ūRäe─Żą═ĪŻ
ĪĪĪĪ▀@śėŠ═īóÖCŲ„╚╦Ą─Ą═╝ēäėū„ūRäe▀BĮėĄĮ┴╦╚╦ŅÉĄ─Ė▀╝ēøQ▓▀Ż¼ūīÖCŲ„╚╦┐╔ęįŽļŽ¾ūį╝║╩Ū╚╦ŅÉüĒīW┴Ģį§├┤öQŲ┐╔wĪŻį┌īŹ“×ųąŻ¼ÖCŲ„╚╦¤oąĶė¢ŠÜŠ═─▄╩╣ė├▀@ą®╚ń║╬öQŲ┐╔wĄ─Ė▀╝ēøQ▓▀ĪŻ
ĪĪĪĪ╚╦éāī”▀@ĘNų¬ūR╣▓ŽĒĄ─Ė∙▒Š└ĒĮŌ▀Ć╠Äė┌│§▓ĮļAČ╬Ż¼╔±ĮøŠWĮj▀Ć╩Ū║▄╔±├žŻ¼─┐Ū░ŲõīŹ╩ŪÅ─║Ļė^ĄĮ╬óė^Ą─ĘĮ╩Įų▓Į▒╗ĮYśŗ╗»Ą─Ż¼į§├┤ĮYśŗ╗»╚ĪøQė┌īŻśIŅIė“Ą─╠ž³c║═─ŃĄ─ąĶŪ¾ĪŻ
ĪĪĪĪĄ½▒Ēš„┐šķgĄ─╣▓ŽĒ╩Ūę╗ĘNĘŪ│ŻėąŽļŽ¾┴”Ą─ĘĮĘ©ĪŻ
ĪĪĪĪ╦³▒Ē├„į┌▒Ēš„┐šķgā╚Ż¼╚╬ęŌ─ŻæBĄ─öĄō■Č╝╩Ū┐╔ęį▀BĮėĄ─Ż¼▀@Š═×ķ▓╗═¼ŅIė“Ą─ų¬ūR▀węŲ║═╚┌║Ž╠ß╣®┴╦ś“┴║Ż¼║▄ūį╚╗Ąžę▓░³└©▓╗═¼ŅÉą═Ą─ÖCŲ„╚╦Ą─╝╝─▄▀węŲĪó═©ė├┤¾šZčį─Żą═┼cīŻė├ÖCŲ„╚╦─Żą═Ą─ų¬ūR╚┌║ŽĄ╚ĪŻ
ĪĪĪĪ╠žäe╩ŪŻ¼ę╗éĆ▓╗│╔╩ņĄ─ŅIė“Ą─ AI ─Żą═Ż¼┐╔ęį═©▀^│╔╩ņĄ─ŅIė“Ą─ AI ─Żą══©▀^║▄ąĪĄ─ė¢ŠÜ┴┐Š═─▄ē“Ą├ĄĮĪŻ
ĪĪĪĪ▀@▒Ń╩ŪŅAė¢ŠÜĄ─┴Ēę╗éĆ└ĒĮŌęĢĮŪĪŻ
ĪĪĪĪėąčąŠ┐Š═▒Ē├„Ż¼į┌┤¾šZčį─Żą═Ą─▒Ēš„┐šķgā╚Ż¼ŽÓ╦ŲĄ─╠ōöM║═¼FīŹĄ─ÖCŲ„╚╦▓┘ū„łDŽ±į┌▒Ēš„┐šķgųąĖ³╝ė┐┐Į³( Ž┬łDųąĄ─ŠG┐“║═ūŽ┐“łDŽ± )Ż¼Č°▓╗═¼Ą─╠ōöM║═¼FīŹĄ─ÖCŲ„╚╦▓┘ū„łDŽ±į┌▒Ēš„┐šķgųąŠ═Ģ■ļxĄ├Ė³╝ė▀h( Ž┬łDųąĄ─╦{┐“║═╝t┐“łDŽ± )ĪŻ

ĪĪĪĪłDį┤Ż║https://arxiv.org/pdf/2405.10020
ĪĪĪĪ╦∙ęįŻ¼═©ė├┤¾─Żą═Ė³ÅVĘ║Ą─¼FīŹ╩└Įńų¬ūRėą═¹Åø║ŽÖCŲ„╚╦ŅIė“ę└┘ć╠ōöMöĄō■įņ│╔Ą─╠ōöM║═¼FīŹĄ─▓ŅŠÓĪŻ
ĪĪĪĪ▒╚╚ńį┌ųŪį¬ÖCŲ„╚╦ GO-1 Š▀╔ĒųŪ─▄┤¾─Żą═ųąŻ¼ęĢėX┤¾šZčį─Żą═ūRäeęĢėX▌ö╚ļŻ¼╚╗║¾š{ė├ąąäėęÄäØīŻ╝ę║═äėū„īŻ╝ęüĒ╔·│╔Ž┬ę╗▓Įäėū„ĪŻ
![]()
ĪĪĪĪłDį┤Ż║https://agibot-world.com/blog/agibot_go1.pdf
ĪĪĪĪį┌─Żą═įOėŗųąŻ¼Ųõ║╦ą─╚į╚╗╩Ūų¬ūR╣▓ŽĒ║═Å═ė├Ż¼ęĢėX┤¾šZčį─Żą═īóų¬ūR╣▓ŽĒĮo┴╦ąąäėęÄäØīŻ╝ę║═äėū„īŻ╝ęŻ¼ąąäėęÄäØīŻ╝ęę▓īóų¬ūR╣▓ŽĒĮo┴╦äėū„īŻ╝ęĪŻ
ĪĪĪĪ─ŻĘ┬īW┴ĢĮY║Ž│¼┤¾öĄō■╝»╩Ūę╗ŚlśO║åČ°ėąą¦Ą─Ą└┬ĘŻ¼▓╗─▄ūC├„╩Ū*Ą─Ż¼Ą½┤_īŹØō┴”śO┤¾Ż¼╗“įSėą═¹Å═┐╠ÖCŲ„╚╦ŅIė“Ą─ ChatGPT Ģr┐╠ĪŻ
ĪĪĪĪ┐éų«Ż¼║åå╬üĒšfŻ¼┤¾─Żą═Ą─═╗ŲŲŻ¼┤¾Ė┼┬╩Ģ■ĦüĒ╚╦ą╬ÖCŲ„╚╦Ą─═╗ŲŲŻ¼ū÷ AIŻ¼Š═╩Ūį┌ū÷ÖCŲ„╚╦Ą─ņ`╗ĻĪŻ

ĪĪĪĪąąśI┘YėŹĪóŲ¾śIäėæBĪóśIĮńė^³cĪóĘÕĢ■╗Ņäė┐╔░l╦═Ó]╝■ų┴news#citmt.cnŻ©░č#ōQ│╔@Ż®ĪŻ
║Żł¾╔·│╔ųą...

