
┤¾öĄō■ AI ŲĮ┼_Ż║śŗų■ Agentic AI Ą─║╦ą─╗∙╩»
ĪĪĪĪ2025─ĻŻ¼AI ╝╝ągėŁüĒ┴╦ęįūįų„ąąäėĪó─┐ś╦ī¦Ž“║═ŁhŠ│Į╗╗ź×ķ╠žš„Ą─ Agentic AI Ģr┤·Ż¼┼c┤╦═¼ĢrŻ¼═Ė▀^ÖCŲ„╚╦Īó▌oų·±{±éĄ╚Ū░čž╠Į╦„Ż¼Å═ļs AI Agent ŽĄĮyę▓š²čĖ╦┘Å─öĄūų╩└Įń▀~Ž“╬’└Ē╩└ĮńĪŻį┌2025įŲŚ½┤¾Ģ■╔ŽŻ¼░ó└’įŲųŪ─▄╝»łFėŗ╦ŃŲĮ┼_žōž¤╚╦═¶▄Ŗ╚A░l▒ĒĪČ┤¾öĄō■ AI ŲĮ┼_Ż║śŗų■ Agentic AI ║╦ą─╗∙╩»ĪĘų„Ņ}č▌ųvŻ¼▓óĦüĒ░ó└’įŲ┤¾öĄō■AIŲĮ┼_ČÓ┐Ņ«aŲĘ╔²╝ē░l▓╝ĪŻ
ĪĪĪĪ═¶▄Ŗ╚A▒Ē╩ŠŻ¼─Żą═ĪóAI╗∙ĄAįO╩®ĪóöĄō■╗∙ĄAįO╩®ĪóČ╦ĄĮČ╦┤ŅĮ©╣żŠ▀╩Ū┬õĄž Agentic AI Ą─ĻPµI╦─ę¬╦žŻ¼░ó└’įŲ┤¾öĄō■ AI ŲĮ┼_ć·└@▀@╦─┤¾ę¬╦ž╠ß╣®ėą┴”Ą─╝╝ągų¦ō╬ĪŻ

ĪĪĪĪ░ó└’įŲųŪ─▄╝»łFėŗ╦ŃŲĮ┼_žōž¤╚╦═¶▄Ŗ╚A¼Fł÷č▌ųv
ĪĪĪĪ╝ė╦┘╩└Įń─Żą═čą░lŻ¼PAI ┼c NVIDIA Physical AI ▄ø╝■ŚŻ║Žū„
ĪĪĪĪį┌┤¾─Żą═─▄┴”╝ė╦┘▀M╗»Ą─Į±╠ņŻ¼│²┴╦═Ų└Ē─Żą═║═Ė„ŅÉ Agentic ─▄┴”į÷ÅŖ─Żą═Ż¼╩└Įń─Żą══¼śėéõ╩▄ĻPūóĪŻ╩└Įń─Żą═─▄ē“└ĒĮŌ║═ū±čŁ╬’└ĒęÄ┬╔Ż¼Š▀éõę“╣¹═Ų└ĒĪóĢrķg═Ųč▌Ą╚─▄┴”Ż¼╩Ū┤¾─Żą═šµš²╔Ņ╚ļ¼FīŹ╬’└Ē╩└ĮńĄ─ĻPµIĪŻ
ĪĪĪĪśŗĮ©“╚½ų¬╚½Ėą”Ą─╩└Įń─Żą═Ż¼ī”╗∙ĄAįO╩®║═ķ_░lŲĮ┼_╠ß│÷┴╦╚½ą┬ę¬Ū¾ĪŻę╗ĘĮ├µŻ¼╩└Įń─Żą═ę└┘ćĄ─öĄō■╠Ä└Ē╣ż│╠Ė³╝ėÅ═ļsŻ¼ąĶę¬▀MąąĘ¹║Ž╬’└ĒęÄ┬╔Ą─ČÓ─ŻæBöĄō■║Ž│╔Īó▀MąąłDŲ¼ęĢŅlŽ“³cįŲ▄ē█EĄ╚░ļĮYśŗ╗»öĄō■Ą─▐DōQĪóęį╝░╔Ņīė┤╬öĄō■└Ēā╚╚▌└ĒĮŌĄ╚;┴Ēę╗ĘĮ├µŻ¼ė╔ė┌śOČ╦ł÷Š░¤oĘ©į┌¼FīŹųą╚½├µ£yįćŻ¼Ę┬šµŲĮ┼_ųžę¬ąįė╚×ķ═╣’@;┤╦═ŌŻ¼ČÓĘN─Żą═ąĶę¬įŲĪó▀ģĪóČ╦ČÓĘNĘ■äšŲĮ┼_ų¦│ųĪŻ
ĪĪĪĪ×ķ┤╦Ż¼░ó└’įŲ┼c NVIDIA š²╩Įą¹▓╝į┌ Physical AI ĘĮŽ“▀_│╔«aŲĘ║Žū„ĪŻPAI īó╝»│╔ NVIDIA Isaac SimĪóIsaac LabĪóNVIDIA CosmosĪóPhysical AI öĄō■╝»į┌ā╚Ą─ NVIDIA Phsyical AI ▄ø╝■ŚŻŻ¼▓óĮY║Ž░ó└’įŲį┌ęÄ─Ż╗»öĄō■ėŗ╦ŃĪóĖ▀ąį─▄AIė¢ŠÜ═Ų└ĒĪó┤¾öĄō■AIę╗¾w╗»ķ_░lĄ╚ŅIė“Ą─¾wŽĄ╗»─▄┴”Ż¼ą╬│╔Ė▓╔wöĄō■ŅA╠Ä└ĒĪóĘ┬šµöĄō■╔·│╔Īó─Żą═ė¢ŠÜįu╣└ĪóÖCŲ„╚╦ÅŖ╗»īW┴ĢĪóĘ┬šµ£yįćį┌ā╚Ą─╚½µ£┬ĘŲĮ┼_ų¦ō╬Ż¼ūī Physical AI ŅIė“ķ_░lš▀│õĘųŽĒ╩▄įŲĄ─ÅŚąį┼cņ`╗ŅŻ¼╚½├µ╝ė╦┘ Physical AI äōą┬┬õĄžĪŻ
ĪĪĪĪ─┐Ū░Ż¼PAI ŲĮ┼_ā╚ęčĮø╔Ž╝▄┴╦▀b▓┘öĄō■▓╔╝»ĪóöĄō■║Ž│╔ĪóöĄō■į÷ÅŖĪóÖCŲ„╚╦─ŻĘ┬īW┴ĢĪó“×ūC£yįć╚½Łh╣Ø╬Õ┤¾ł÷Š░Ą─ūŅ╝čīŹ█`Ż¼ęį Notebook ą╬╩Į╣®ķ_░lš▀ķ_Žõ╝┤ė├ĪŻ

ĪĪĪĪ░ó└’įŲ x NVIDIA║Žū„░l▓╝
ĪĪĪĪŅAė¢ŠÜĪó║¾ė¢ŠÜĪó═Ų└Ē╚½┴„│╠ā×╗»Ż¼AI ╗∙ĄAįO╩®į┘╔²╝ē
ĪĪĪĪū„×ķ╚½ŚŻ╚╦╣żųŪ─▄Ę■äš╔╠Ż¼░ó└’įŲ╝µŠ▀ŅIŽ╚Ą─ūįčą┤¾─Żą═Īó╗Ņ▄SĄ─ķ_į┤─Żą═╔·æB┼cÅŖ┤¾Ą─ AI Infra ¾wŽĄĪŻæ¬ī”ą┬Ą──Żą═╝▄śŗ║═ėŗ╦Ń╠ž³cŻ¼░ó└’įŲ╚╦╣żųŪ─▄ŲĮ┼_PAI┼c═©┴x┤¾─Żą═┬ō║Žā×╗»Ż¼ėĪūC┴╦╚½ŚŻAI“1+1>2”Ą─ą¦╣¹ĪŻ
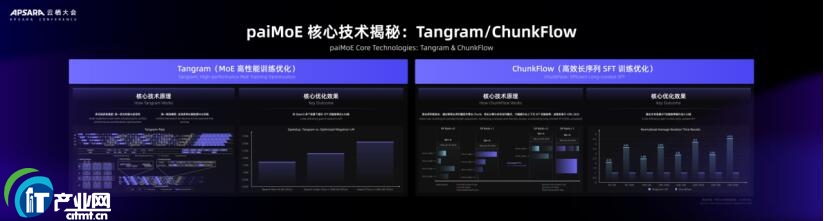
ĪĪĪĪßśī” MoE ╝▄śŗ─Żą═Ż¼PAI ═Ų│÷┤¾ęÄ─Ż MoE ė¢ŠÜę²Ūµ paiMoEŻ¼▓╔ė├Įyę╗š{Č╚ÖCųŲĪóūį▀mæ¬ėŗ╦Ń═©ą┼č┌╔wĪóEP ėŗ╦Ńžō▌dŠ∙║Ō║═ėŗ╦Ń’@┤µĘųļx╩Į▓󹹥╚ā×╗»╩ųČ╬Ż¼ėąą¦ĮŌøQ╣żū„žō▌d▓╗═¼ĪóŽĪ╩Ķ MoE ═©ą┼š╝▒╚Ė▀Ą╚å¢Ņ}Ż¼į┌ Qwen3 ė¢ŠÜ▀^│╠ųąīŹ¼FČ╦ĄĮČ╦╝ė╦┘▒╚╠ßą¦ 3 ▒ČŻ¼ė¢ŠÜ MFU │¼▀^ 61%ĪŻ

ĪĪĪĪ─┐Ū░Ż¼paiMoE ę²Ūµā╔ĒŚ║╦ą─╝╝ąg Tangram ║═ ChunkFlow ęčį┌ Qwen ╚½ŽĄ─Żą═Ą─ CPT/SFT ļAČ╬ū„×ķ─¼šJĘĮ░ĖŻ¼Tangram ų¦│ųų¦│ųČÓśė╗»╝Ü┴ŻČ╚ MoE ė¢ŠÜ╚╬䚯¼ę╗╠ūÖCųŲų¦│ų▓╗═¼Ą─ėŗ╦ŃĪó═©ą┼Īó’@┤µ┼cžō▌dŠ∙║ŌąĶŪ¾ĪŻChunkFlow ßśī”╠Ä└ĒūāķL║═│¼ķLą“┴ąöĄō■Ą─ąį─▄å¢Ņ}Ż¼╠ß│÷┴╦ęį Chunk ×ķųąą─Ą─ė¢ŠÜÖCųŲĪŻūāķLą“┴ąöĄō■ųžą┬ĮM┐Ś×ķĄ╚ķL Chunk ▓óŪęĮY║Žš{Č╚Ż¼ėąą¦╠ß╔²ė¢ŠÜą¦┬╩Ż¼čąŠ┐│╔╣¹▒╗ICML 2025 ╩šõøĪŻ
ĪĪĪĪßśī” DiT ╝▄śŗ─Żą═Ż¼PAI ═Ų│÷ė¢ŠÜ═Ų└Ēę╗¾w╗»╝ė╦┘ę²Ūµ paiFuserŻ¼═©▀^ėŗ╦ŃłDā×╗»Īó’@┤µÅ═ė├Īó═©ą┼ē║┐sĪóäėæBš{Č╚Ą╚╩ųČ╬Ż¼’@ų°ĮĄĄ═┘Yį┤Ž¹║─Ż¼╠ß╔²ŽĄĮy═╠═┬ĪŻį┌8┐©▓óąą═Ų└Ēł÷Š░Ž┬Ż¼ęĢŅl╔·│╔║─ĢrūŅĖ▀£p╔┘80%ęį╔ŽŻ¼į┌▒ŻšŽ«ŗ┘|Ū░╠ߎ┬īŹ¼F“ĘųńŖ╝ē”╔§ų┴“├ļ╝ē”▌ö│÷Ż¼×ķČ╠ęĢŅl╔·«aĪó│┴Į■╩ĮVRĪóAIGCäōęŌ╣żŠ▀Ą╚Ģrą¦├¶Ėąą═śIäš╠ß╣®łįīŹĄūū∙ĪŻ
ĪĪĪĪį┌═Ų└ĒīėŻ¼═©▀^┤¾ęÄ─ŻEPĪóPD/AFĘųļxĪóÖÓųžā×╗»ĪóLLMųŪ─▄┬Ęė╔į┌ā╚Ą─╚½µ£┬Ęā×╗»Ż¼īŹ¼F═Ų└Ēą¦┬╩’@ų°╠ß╔²Ż║═Ų└Ē═╠═┬TPSį÷╝ė71%Ż¼ĢrčėTPOTĮĄĄ═70.6%Ż¼öU╚▌ĢrķLĮĄĄ═97.6%ĪŻ┤╦═ŌŻ¼PAI-EAS ųž░§═Ų│÷Ų¾śI╝ē EP ĮŌøQĘĮ░ĖŻ¼ų·┴”Ū¦ā|ģóöĄ MoE ─Żą═ęįĖ³Ą═Ą─│╔▒ŠĪóĖ³Ė▀Ą─ą¦┬╩Ę■äšė┌ŠĆ╔ŽśIäšĪŻ

ĪĪĪĪ┤¾öĄō■ŲĮ┼_╚½├µų¦│ų AI ėŗ╦Ń║═Ę■äš
ĪĪĪĪ¤ošō╩Ū─Żą═ė¢ŠÜ▀Ć╩Ū═Ų└ĒŻ¼Č╝ļx▓╗ķ_öĄō■Ą─ų¦ō╬ĪŻ░ó└’įŲ┤¾öĄō■ŲĮ┼_ą¹▓╝├µŽ“ AI «aŲĘ▀Mąą╚½ą┬╔²╝ēŻ¼╚½├µų¦│ųAIėŗ╦Ń║═Ę■äšĪŻ

ĪĪĪĪ┤¾öĄō■ŲĮ┼_ MaxComputeĪóHologresĪóEMRĪóFlink Ą╚«aŲĘöĄō■╠Ä└Ē╚½├µų¦│ų AI FunctionŻ¼īóAI─▄┴”╔ŅČ╚╝»│╔ų┴é„ĮyöĄō■╠Ä└Ē┴„│╠ĪŻį┌SQL╗“Pythonū„śIųąŻ¼š{ė├AI─Żą═╚ń═¼š{ė├Ųš═©║»öĄŻ¼īŹ¼FöĄō■╠Ä└Ē┼cAI═Ų└ĒĄ─¤o┐p╚┌║ŽĪŻMaxFrame═Ų│÷├µŽ“AIł÷Š░Ą─ą┬ę╗┤·įŁ╔·Ęų▓╝╩ĮPythonę²ŪµDPEŻ¼öĄō■╠Ä└Ēąįār▒╚╠ß╔²1▒ČŻ¼ų¦│ųöĄō■ŅA╠Ä└ĒŻ¼MLė¢ŠÜ═Ų└ĒŻ¼«Éśŗ┘Yį┤ėŗ╦ŃŻ¼PythonįŁ╔·UDFęį╝░AI FunctionĄ╚ėŗ╦Ńł÷Š░ĪŻ
ĪĪĪĪĖ„ąąĖ„śIČ╝ÅVĘ║ąĶę¬ČÓ─ŻĘų╬÷Öz╦„Ż¼┤¾öĄō■ŲĮ┼_ų┬┴”ė┌┤“įņAIæ¬ė├Ą─ų¬ūRÖz╦„ŽĄĮyŻ¼ūīöĄō■░lō]Ė³┤¾Ą─ārųĄĪŻEMR-Starrocks ╚½ą┬ų¦│ų╚½╬─Öz╦„Ż¼OpenSearch GPUīŹ└²“īäėŽ“┴┐╦„ę²śŗĮ©Ż¼š¹¾wąįār▒╚╠ß╔²10▒ČŻ¼MilvusĪóElasticSearchĪóHologresų¦│ųŽ“┴┐+╚½╬─╗ņ║ŽÖz╦„Ż¼ŲõųąHologres ░l▓╝╚½ą┬Ž“┴┐╦„ę² HGraphŻ¼ĄŪĒö VectorDBBench ąįār▒╚░±å╬ QPSĪóRecallĪóLatencyĪóLoad ╦─ĒŚĄ┌ę╗ĪŻ
ĪĪĪĪį┌öĄō■▀\ŠSĘĮ├µŻ¼┤¾öĄō■ŲĮ┼_DataWorksĪóMaxComputeĪóHologresĪóEMRĄ╚«aŲĘ═Ų│÷═©▀^ūį╚╗šZčįĮ╗╗ź╝┤┐╔īŹ¼FöĄō■ķ_░lĪó▀\ŠSĄ╚▓┘ū„Ą─ųŪ─▄╗»Į╗╗ź╩Į«aŲĘ─▄┴”Ż¼░l▓╝ Data Agent ĮM╝■Ż¼╚½├µīŹ¼F Agentic╗»ĪŻ
ĪĪĪĪ┤¾öĄō■ŲĮ┼_į┌ČÓĒŚć°ļHįu£yųąĄŪĒö░±å╬ĪŻ
ĪĪĪĪĪ± ░ó└’įŲ PAI ┼c DataWorks łFĻĀAgentic į┌NL2SQLĄ─ Spider 2.0-Snow įu£yųąŻ¼ęį 61.24%Ą─ł╠ąą£╩┤_┬╩śs½@░±å╬Ą┌ę╗ĪŻ
ĪĪĪĪĪ± EMR śs½@ā╔ĒŚć°ļH░±╩ūŻ¼ Fusion Ż©Ų¾śI╝ē Spark ā╚║╦Ż® ║═ Stella (Ų¾śI╝ē StarRocks ā╚║╦) ╝╝ągĄŪĒö TPC ╚½Ū“░±å╬ĪŻŲõųąEMR Serverless Sparkį┌TPC-DS 100TB£yįćųąŻ¼ęį QphDS ąį─▄╠ß╔²100%Ą─│╔┐āŖZ╣┌ĪŻ
ĪĪĪĪĪ± Hologres ╚½ą┬Ž“┴┐╦„ę² HGraph ĄŪĒö VectorDB Benchmark ░±å╬Ż¼1000 ╚fŽ“┴┐š┘╗žöĄō■╝»į┌š┘╗ž┬╩Ą┌ę╗Ą─ŪķørŽ┬Ż¼QPS ęÓ╚½Ū“Ą┌ę╗ĪŻ

ĪĪĪĪśŗĮ© AI öĄō■Ąūū∙Ż¼OpenLake ├µŽ“╚½─ŻæBöĄō■┴┐╔ĒČ©ųŲ
ĪĪĪĪį┌ Agentic AI Ģr┤·Ż¼░ó└’įŲOpenLake═¼śė▀Mąą┴╦╚½ĘĮ╬╗╔²╝ēŻ¼ØMūŃ┐═æ¶├µī”╬’└Ē╩└Įń╚½─ŻæBöĄō■Ģr╦∙ąĶĄ─ę╗¾w╗»öĄō■┤µā”║═╣▄└ĒŽĄĮyĪŻ
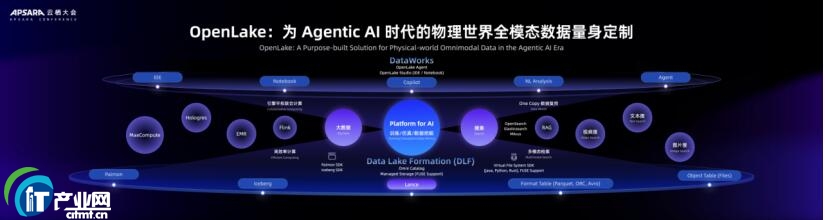
ĪĪĪĪDLF 3.0 ═žš╣╚½─ŻæBöĄō■ų¦│ųŻ¼║■é}─┐õøĘ■äš(DLF)ū„×ķ║■é}┤µā”īėĮyę╗╣▄└Ē║╦ą─Ż¼īó┤µā”Ė±╩ĮÅ─é„ĮyĮYśŗ╗»öĄō■Ż¼═žš╣ų┴╚½─ŻæBöĄō■ł÷Š░Ż¼ų¦│ų├µŽ“ AI ł÷Š░Ą─ LanceĪóIcebergęį╝░╬─╝■öĄō■ĪóĖ±╩Į╗»▒ĒĖ±öĄō■Ą╚╚½ŅÉą═ĪŻ
ĪĪĪĪėŗ╦Ń╔·æBĘĮ├µŻ¼OpenLake ═©▀^ČÓę²ŪµŲĮÖÓ┬ō║Žėŗ╦Ń╝▄śŗŻ¼┐╔īŹ¼FöĄō■¤oąĶ░ß╝ęĪóČÓę²Ūµģf═¼╠Ä└ĒŻ¼║■é}┤µā”īė(DLF+Managed Storage)ū„×ķå╬ę╗Ę▌öĄō■į┤Ż¼Ž“╔Žī”Įė╚½µ£┬Ę┤¾öĄō■&AI ę²ŪµĪŻOpenLake═¼Ģr ═Ų│÷ OpenLake Studio ČÓ─ŻæB Data&AI ę╗¾w╗»ķ_░lŲĮ┼_Ż¼īŹ¼Fę╗šŠ╩ĮöĄō■ķ_░l-ų╬└Ē-▀\ŠSķ]ŁhŻ¼ĮĄĄ═ČÓ─ŻæBöĄō■+AI Ą─ķ_░lķTÖæĪŻ
ĪĪĪĪ╠į╠ņ╝»łFį┌├µ┼RöĄō■╣┬ŹuĪóČÓę²Ūµģf═¼Īó▀\ŠS│╔▒ŠĖ▀Ą╚å¢Ņ}╔ŽŻ¼▓╔ė├OpenLake “┤µā”īėĮyę╗→ėŗ╦Ńīėš¹║Ž→║■┴„ę╗¾w╗»”Ą─╝╝ąg┬ĘÅĮŻ¼ūŅĮKīŹ¼F“īŹĢr╗»Īóę╗¾w╗»ĪóĄ═│╔▒ŠĪóĖ▀ą¦┬╩”Ą─öĄō■║■é}╔²╝ē─┐ś╦Ż¼×ķśIäšäōą┬┼cĮĄ▒Š╠ßą¦╠ß╣®┴╦łįīŹöĄō■╗∙ĄAĪŻ
ĪĪĪĪAgentic Search ░l▓╝Ż║AI ╦č╦„▀~╚ļūįų„ģfū„Ģr┤·
ĪĪĪĪ┤¾─Żą═Ą─▒¼░l╩Į░lš╣Ż¼é„Įy╦č╦„┴„┴┐ųØu▐DŽ“AI“īäėĄ─╦č╦„╣żŠ▀Ż¼▀@ę╗▐Dūā▒│║¾īóųžśŗė├æ¶╦č╦„Ą─Į╗╗ź▀ē▌ŗĪóöĄō■ą╬æB┼c╝╝ąg╝▄śŗĪŻ×ķ┤╦Ż¼░ó└’įŲš²╩Į░l▓╝ Agentic Search╝▄śŗŻ¼įō╝▄śŗ═©▀^ČÓAgentģf═¼ĪóČÓ─ŻæBöĄō■╠Ä└Ē┼c╚╬äšūįų„ęÄäØŻ¼śŗĮ©┴╦Å─“å¢Ņ}╠ß│÷”ĄĮ“ĘĮ░Ėūįų„╔·│╔”Ą─ųŪ─▄ķ]ŁhŻ¼ča²RīŹ¼FAgentict AIĄ─ūŅ║¾ę╗╣½└’ĪŻ
ĪĪĪĪČÓ─ŻæBöĄō■╠Ä└ĒŻ║ų¦│ų╬─ÖnĪółDŽ±Īó┤·┤aĪóęĢŅlĄ╚ā╚╚▌Ą─ĮŌ╬÷ĪóīŹ¾w│ķ╚Ī┼cŽ“┴┐╗»Ż¼Ė▓╔wŽ“┴┐ę²ŪµĪóöĄō■ÄņĪóų¬ūRłDūVĄ╚ČÓę²Ūµģf═¼;
ĪĪĪĪūįų„╚╬äšęÄäØŻ║ę└═ąQwen3┤¾─Żą═┼cČ╠Ų┌/ķLŲ┌ėøæø─▄┴”Ż¼ų„Agent┐╔äėæBš{ė├Code AgentĪóBrowser AgentĄ╚╣żŠ▀Ż¼īŹ¼FÅ═ļså¢┤┼cČÓ╠°═Ų└Ē;
ĪĪĪĪÖÓ═■£yįćŅIŽ╚Ż║į┌OpenAIĄ─BrowseComp┼cDeep Researchįu£y╝»ųąŻ¼Agentic SearchÖz╦„┼c═Ų└Ē─▄┴”│¼įĮGeminiĪóOpenAIĄ╚ć°ļHų„┴„ĘĮ░ĖŻ¼Å═ļs╚╬䚣╩┤_┬╩╠ß╔²│¼40%ĪŻ
ĪĪĪĪųŪ─▄▌oų·±{±é&ÖCŲ„╚╦öĄō■ŅA╠Ä└Ē┼c─Żą═ė¢═ŲĮŌøQĘĮ░Ė░l▓╝
ĪĪĪĪĖ∙ō■ŽÓĻPŅA£yŻ¼2025─Ļ L2+ ▄ćą═õN┴┐īóÅ─100╚f▌v’j╔²ų┴1000╚f▌vĪŻųŪ─▄▌oų·±{±éĄ─ÅVĘ║æ¬ė├ĦüĒ┴╦║Ż┴┐öĄō■Ż¼į┌╝╝ąg╝▄śŗīė├µŻ¼ę▓š²ĮøÜvÅ─é„ĮyĘųļAČ╬ąĪ─Żą═╝▄śŗŽ“Č╦ĄĮČ╦ČÓ─ŻæB┤¾─Żą═Ą─╝╝ągĘČ╩Į▀węŲŻ¼«öŪ░ųŪ±{ŽĄĮyīŹ¼F┴╦Ėąų¬ĪóøQ▓▀Īó┐žųŲ─ŻēKĄ─╔ŅČ╚±Ņ║ŽĪŻ▀@ę▓═ŲäėĄūīėĄ─┤¾öĄō■AI╣ż│╠╝▄śŗ▓╗öÓ╔²╝ēŻ¼┤┘╩╣öĄō■╩š╝»ĪóöĄō■╠Ä└ĒĪó─Żą═ė¢ŠÜĪó─ŻĘ┬īW┴ĢĪóĘ┬šµ“×ūCį┌ā╚Ą─╣ż│╠µ£┬Ę▀Mę╗▓Į╚┌║ŽĪŻ═¼ĢrŻ¼╬ęéāį┌ÖCŲ„╚╦čą░l┬õĄžĄ─ł÷Š░ųąŻ¼ę▓░l¼F┴╦ŽÓ╦ŲĄ─┌ģä▌┼cąĶŪ¾ĪŻ
ĪĪĪĪ░ó└’įŲ┼c┐═æ¶į┌╣▓Į©ųŪ─▄«aŠĆĄ─▀^│╠ųąŻ¼┐éĮY▓ó░l▓╝┴╦├µŽ“ųŪ─▄▌oų·±{±é║═ÖCŲ„╚╦čą░lĄ─öĄō■╠Ä└Ē┼c─Żą═ė¢═ŲĮŌøQĘĮ░ĖĪŻ

ĪĪĪĪĘĮ░ĖĄūīėĮyę╗Ą─į¬öĄō■╣▄└Ē(DLF)īŹ¼Fī”░┘PB╝ēöĄō■Ą─Ė▀ą¦╣▄┐žŻ¼’@ų°ĮĄĄ═ę“öĄō■éõĘ▌Īó┴„äė║═╠Ä└ĒĦüĒĄ─│╔▒ŠŻ¼▓ó╠ß╔²╠Ä└Ēą¦┬╩ĪŻöĄō■āHąĶ┤µā”ę╗Ę▌Ż¼╝┤┐╔▒╗ČÓĘNėŗ╦Ńę²Ūµš{ė├Ż¼ĮY║ŽŠÅ┤µ╝ė╦┘┼c╚½─ŻæBē║┐s╝╝ągŻ¼▀Mę╗▓Įā×╗»čą░l┴„│╠ĪŻ
ĪĪĪĪöĄō■╠Ä└Ēę└═ąMaxFrame/Spark/RayĄ╚Ęų▓╝╩Įėŗ╦Ńę²ŪµŻ¼į┌CPU/GPU«Éśŗ╝»╚║ųąīŹ¼FĖ▀ą¦š{Č╚┼c┘Yį┤Å═ė├Ż¼▓óĮĶų·Data Juicer╦Ńūė┐“╝▄╝ė╦┘ŅA╠Ä└ĒĪŻĮøŅA╠Ä└Ē╔·│╔Ą─ė¢ŠÜśė▒ŠŻ¼═©▀^┤¾─Żą═öĄō■═┌Š“«a╔·ą┬ś╦║×┼cEmbeddingĪŻĘĮ░Ė╠ß╣®ūįčą┼cķ_į┤ā╔╠ūÖz╦„ę²ŪµŻ¼ų¦│ųį┌░┘PBöĄō■ųą┐ņ╦┘Öz╦„╦∙ąĶśė▒ŠĪŻ
ĪĪĪĪį┌─Żą═ė¢ŠÜ┼c═Ų└ĒļAČ╬Ż¼╚╦╣żųŪ─▄ŲĮ┼_ PAI ╝░ paiTurboX ╝ė╦┘┐“╝▄═©▀^ČÓŽĄĮy┬ō║Žā×╗»Ż¼īŹ¼Fų┴Ė▀3▒Čąį─▄╠ß╔²Ż¼ūŅ┤¾╗»ė▓╝■┘Yį┤└¹ė├┬╩Ż¼╠ß╔²čą░lą¦ęµĪŻ
ĪĪĪĪū┐±S╩Ūć°ļHŅIŽ╚Ą─ųŪ─▄▌oų·±{±é╣®æ¬╔╠Ż¼╠ß╣®ąąśIę╗┴„Ą─┴┐«a▌oų·±{±é║═Ė▀╝ēäeųŪ─▄▌oų·±{±éŽĄĮy(Ė▓╔wL2~L4)Ż¼ęč┼c┤¾▒ŖŲ¹▄ćĪó╔ŽŲ¹═©ė├╬Õ┴ŌĪó▒╚üåĄŽĪóŲµ╚Ų¹▄ćĪóķL│ŪŲ¹▄ćĄ╚╩«ėÓŲ¹▄ćŲĘ┼Ų▀_│╔╔ŅČ╚║Žū„Ż¼┬ō║Ž═Ų│÷ 30 ėÓ┐Ņ┴┐«aą┬▄ćą═Ż¼▀Ćėą 30 ČÓ┐Ņ▄ćą═╝┤īó┴┐«a┬õĄžĪŻį┌ųŪ±{ŽĄĮyūŅ║╦ą─Ą─╦ŃĘ©ĘĮ├µŻ¼ū┐±Säōą┬ąįĄž▓╔ė├Č╦ĄĮČ╦╩└Įń─Żą═║═VLAĘĮ░ĖŻ¼╗∙ė┌ūį╗žÜw╝▄śŗ║═ÅŖ╗»īW┴ĢŻ¼īŹ¼FųŪ±{ŽĄĮyĄ─Scaling LawŻ¼▓╗āHīŹ¼F░▓ą─öM╚╦Ą─±{±é¾w“ׯ¼ę▓×ķė├æ¶╠ß╣®±{±éAgentĄ─ųŪ─▄╗»Į╗╗ź¾w“×ĪŻ
ĪĪĪĪū┐±S AI ╩ūŽ»╝╝ąg╣┘ĻÉĢįųŪ▒Ē╩ŠŻ¼ę└═ą░ó└’įŲŻ¼ū┐±S┤ŅĮ©┴╦│¼▀^ 3 EFLOPS Ą─ AI ųŪ╦ŃŲĮ┼_║═┤¾öĄō■ŲĮ┼_Ż¼ų¦ō╬╩«ā|╝ēäeĄ─ł÷Š░öĄō■╠Ä└ĒĪó╚½ŠSČ╚Ą─śIäšČ┤▓ņĪóęį╝░Č╦ĄĮČ╦╩└Įń─Żą═╝░VLA─Żą═Ą─Ė▀ą¦ė¢ŠÜĪŻ╬┤üĒŻ¼ū┐±Sīóöy╩ų░ó└’įŲŻ¼│ų└m┤“įņ╚½Ū“ŅIŽ╚Īó╚½Ū“╣▓ŽĒĄ─ųŪ─▄▌oų·±{±éŽĄĮyĪŻ

ĪĪĪĪū┐±S AI ╩ūŽ»╝╝ąg╣┘ĻÉĢįųŪ¼Fł÷č▌ųv
ĪĪĪĪūįūā┴┐ÖCŲ„╚╦╩Ūć°ā╚ūŅįń▓╔ė├═Ļ╚½Č╦ĄĮČ╦┬ĘÅĮīŹ¼F═©ė├Š▀╔ĒųŪ─▄┤¾─Żą═Ą─ÖCŲ„╚╦╣½╦Šų«ę╗Ż¼Ųõūį蹥─Š▀╔ĒųŪ─▄┤¾─Żą═ WALL-A Š▀éõūįų„Ėąų¬Īó═Ų└ĒĪóķL│╠øQ▓▀Į╗╗źĪó╩└Įń─Żą═┼cĖ▀Š½Č╚Å═ļs▓┘ū„─▄┴”Ż¼ČÓéĆŠSČ╚─▄┴”╠Äė┌╚½Ū“ŅIŽ╚╦«ŲĮĪŻ╗∙ė┌ūį蹥─╗∙ĄA─Żą═Ż¼ūįūā┴┐═Ų│÷╚½ūįčąĖ▀ūįė╔Č╚ņ`Ū╔╩ųĪó▌å╩Įļp▒█Ę┬╚╦ą╬ÖCŲ„╚╦“┴┐ūė2╠¢(Quanta X2)Ą╚ė▓╝■Ż¼ęčį┌ČÓ▓Į¾EÅ═ļs╚╬äšł÷Š░ųąų▓Į┬õĄžæ¬ė├ĪŻ
ĪĪĪĪÖCŲ„╚╦╩ŪĖ▀Č╚Ęų╔ó╩ĮĄ─ĮKČ╦Ż¼Ą½ėųąĶę¬║═įŲŠo├▄ĮY║ŽĪŻūįūā┴┐äō╩╝╚╦&CEO ═§Øō▒Ē╩ŠŻ¼“╬ęéāąĶę¬╦Ń┴”Īó┤¾öĄō■Īó╚╦╣żųŪ─▄ŲĮ┼_╚²╬╗ę╗¾wĄ─Īó▀mė├ė┌Š▀╔ĒųŪ─▄Ą─įŲ╔ŽAI╗∙ĄAįO╩®╝▄śŗĪŻ░ó└’įŲņ`╗ŅĪóĖ▀ąį─▄Ą─┤¾öĄō■ AI ŲĮ┼_Ż¼─▄ē“═Ļ├└Ę¹║Ž▓óØMūŃÖCŲ„╚╦öĄō■ŅA╠Ä└ĒĪóĘų▓╝╩Į▓┐╩ĪóĘų▓╝╩Įė¢ŠÜĪóöĄō■┤¾ęÄ─Ż▀h│╠╗žé„Ą╚Ė„ĘĮ├µĄ─ąĶŪ¾Ż¼śO┤¾╠ß╔²čą░l╝░─Żą═Ą³┤·ą¦┬╩ĪŻ”

ĪĪĪĪūįūā┴┐äō╩╝╚╦&CEO ═§Øō¼Fł÷č▌ųv

ĪĪĪĪąąśI┘YėŹĪóŲ¾śIäėæBĪóśIĮńė^³cĪóĘÕĢ■╗Ņäė┐╔░l╦═Ó]╝■ų┴news#citmt.cnŻ©░č#ōQ│╔@Ż®ĪŻ
║Żł¾╔·│╔ųą...

