
Data Warebase │╔╣”č║ūó PostgreSQL ╔·æB(t©żi)Ż¼╗“│╔ AI Ģr(sh©¬)┤·öĄ(sh©┤)ō■(j©┤)Ąūū∙
ĪĪĪĪū„š▀ | ═§ĮB┬Q @ProtonBase
ĪĪĪĪ▒Š╬─ā╚(n©©i)╚▌š¹└Ēūį ProtonBase CEO ═§ĮB┬Qį┌ AICon Ą─ų„Ņ}č▌ųvĪČData Warebase: Instant Ingest-Transform-Explore-Retrieve for AI ApplicationsĪĘĪŻū„š▀Ą─┬ÜśI(y©©)Įø(j©®ng)Üvž×┤®┴╦ AI 1.0Īó2.0 ║═ 3.0 Ą─Ģr(sh©¬)┤·Ż¼Å─╦č╦„═Ų╦]Ż¼ĄĮęĢėX(ju©”) / šZ(y©│)ę¶ / NLP ųŪ─▄Ż¼į┘ĄĮ«ö(d©Īng)Ū░š²╚½┴”═Č╚ļĄ─┤¾─Żą═ AI └╦│▒Ż¼▒Š╬─īóĮY(ji©”)║ŽŲõČÓ─ĻüĒ(l©ói)ī”(du©¼)öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®Ą─īŹ(sh©¬)█`┼cĘ┤╦╝Ż¼╔Ņ╚ļ╠Įėæ╔·│╔╩Į AI Ģr(sh©¬)┤·ī”(du©¼)öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)╠ß│÷Ą─╚½ą┬╠¶æ(zh©żn)┼cØōį┌ÖC(j©®)ė÷ĪŻ
ĪĪĪĪ╬─š┬ĮY(ji©”)śŗ(g©░u)Ż║
ĪĪĪĪ·TrendingŻ║öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®į┌ AI Ģr(sh©¬)┤·Ą─ą┬┌ģä▌(sh©¼)
ĪĪĪĪ·Introducing Data WarebaseŻ║╩▓├┤╩Ū Data Warebase
ĪĪĪĪ·Data Warebase for AI WorkloadŻ║╚ń║╬ų¦ō╬ AI ╣żū„žō(f©┤)▌d
ĪĪĪĪ·Use Cases of Data WarebaseŻ║Ąõą═┬õĄžł÷(ch©Żng)Š░
ĪĪĪĪ·The Difference Between Data Warebase and Other TechnologiesŻ║┼c¼F(xi©żn)ėą╝╝ąg(sh©┤)Ą─▓Ņ«É┼cā×(y©Łu)ä▌(sh©¼)
ĪĪĪĪTrendingŻ║öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®į┌ AI Ģr(sh©¬)┤·Ą─ą┬┌ģä▌(sh©¼)
ĪĪĪĪ╬┤üĒ(l©ói)Ą─╦∙ėąæ¬(y©®ng)ė├Ż¼īóų„ę¬ī”(du©¼)Įėā╔éĆ(g©©)Įė┐┌Ż║ę╗éĆ(g©©) Data APIŻ¼ę╗éĆ(g©©) AI APIĪŻ
ĪĪĪĪ╩ūŽ╚Ż¼╗žŅÖę╗Ž┬Į³Ų┌į┌öĄ(sh©┤)ō■(j©┤)ŅI(l©½ng)ė“ęį╝░ Data for AI ŅI(l©½ng)ė“Ą─ŽÓĻP(gu©Īn)╦╝┐╝ĪŻ▀@Č╬Ģr(sh©¬)ķg└’Ż¼ėą╚²Ślųž┤¾ą┬┬äĖ±═Ōę²╚╦ūó─┐Ż║

ĪĪĪĪĄ┌ę╗Ż¼NeonŻ║Databricks ęį 10 ā|├└į¬╩š┘Å(g©░u) Neon Ą─┼e┤ļį┌ąąśI(y©©)ā╚(n©©i)ę²░l(f©Ī)┴╦ÅVĘ║ĻP(gu©Īn)ūóĪŻ─┐Ū░Ż¼╚½Ū“ūŅŠ▀ė░Ēæ┴”Ą─öĄ(sh©┤)ō■(j©┤)╣½╦Š¤o(w©▓)ę╔╩Ū Snowflake ║═ Databricks——╦³éā▓╗āHį┌öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®ŅI(l©½ng)ė“š╝ō■(j©┤)║╦ą─Ąž╬╗Ż¼ę▓š²│╔×ķ▒ŖČÓŲ¾śI(y©©)śŗ(g©░u)Į© AI ─▄┴”Ą─ĻP(gu©Īn)µIŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪĄ┌Č■Ż¼Supabaseį┌ 4 į┬Ąūą¹▓╝═Ļ│╔ą┬ę╗▌å╚┌┘YŻ¼ĮŅ~Ė▀▀_(d©ó) 2 ā|├└į¬Ż¼╣└ųĄę▓ļSų«┼╩╔²ų┴ 20 ā|├└į¬ĪŻ┼c┤╦═¼Ģr(sh©¬)Ż¼╩ął÷(ch©Żng)╔Žé„│÷ėąČÓ╝ę┐Ų╝╝Š▐Ņ^ėąęŌ╩š┘Å(g©░u) Supabase Ą─Ž¹ŽóŻ¼¤o(w©▓)ę╔×ķöĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®ŅI(l©½ng)ė“ūó╚ļ┴╦ą┬Ą─╗Ņ┴”┼cĻP(gu©Īn)ūóČ╚ĪŻ
ĪĪĪĪĄ┌╚²Ż¼ClickHouseę▓═Ļ│╔┴╦ūŅą┬ę╗▌å╚┌┘YŻ¼╣└ųĄęč│¼ 60 ā|├└į¬ĪŻÅ─Ųõī”(du©¼)═Ōą¹ĘQĄ──┐ś╦(bi©Īo)üĒ(l©ói)┐┤Ż¼ClickHouse ╦Ų║§ęčĮø(j©®ng)£╩(zh©│n)éõ║├Ž“ Snowflake ░l(f©Ī)Ų╠¶æ(zh©żn)ĪŻ
ĪĪĪĪĮėŽ┬üĒ(l©ói)Ż¼╬ęīóĘųŽĒ╬ęī”(du©¼)▀@╚²╝ę╣½╦ŠĮ³Ų┌×ķ║╬éõ╩▄┘Y▒ŠŪÓ▓AĪóŅlŅl½@Ą├═Č┘YĪó╩š┘Å(g©░u)ĻP(gu©Īn)ūóĄ─Äū³c(di©Żn)ė^▓ņ┼c╦╝┐╝ĪŻ
ĪĪĪĪ┌ģä▌(sh©¼)ę╗Ż║┤¾šZ(y©│)čį─Żą═Ą─│÷¼F(xi©żn)š²į┌ŅŹĖ▓é„Įy(t©»ng)ĘČ╩Į
ĪĪĪĪį┌╬ęļxķ_(k©Īi)▀_(d©ó)─”į║ų«Ū░Ż¼▒M╣▄Ųõį┌šZ(y©│)ę¶ūR(sh©¬)äe║═ūį╚╗šZ(y©│)čį╠Ä└Ē(NLP)Ą╚ŅI(l©½ng)ė“ęč▓╔ė├┴╦┤¾šZ(y©│)čį─Żą═(LLM)Ą─╝╝ąg(sh©┤)┬ĘŠĆŻ¼Ą½«ö(d©Īng)Ģr(sh©¬)╔ą╬┤ćLįć╩╣ė├ LLM ī”(du©¼)╚½ŠW(w©Żng)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąĮy(t©»ng)ę╗ė¢(x©┤n)ŠÜĪŻų▒ĄĮ OpenAI Ą─│╔╣”┬õĄžŻ¼š¹éĆ(g©©)ąąśI(y©©)▓┼šµš²ęŌūR(sh©¬)ĄĮ▀@ĘNĘĮ╩ĮĄ─┐╔ąąąį┼cĖ’├³ąįĪŻļSų«Č°üĒ(l©ói)Ą─╩ŪŻ¼Äū║§╦∙ėą╝╝ąg(sh©┤)╣½╦ŠČ╝ķ_(k©Īi)╩╝ōĒ▒¦┤¾šZ(y©│)čį─Żą═Ż¼īó║Ż┴┐öĄ(sh©┤)ō■(j©┤)ģRŠ█į┌ę╗ŲŻ¼ĮĶų·┤¾šZ(y©│)čį─Żą═Ą──▄┴”×ķ├┐éĆ(g©©)╚╦╗ž┤╚š│Żå¢(w©©n)Ņ}Ż¼ųžśŗ(g©░u)╚╦ÖC(j©®)Į╗╗ź¾w“×(y©żn)ĪŻ
ĪĪĪĪĄ½Å─┌ģä▌(sh©¼)üĒ(l©ói)┐┤Ż¼╬┤üĒ(l©ói)Š▀éõ─▄┴”ė¢(x©┤n)ŠÜ┤¾─Żą═Ą─Ų¾śI(y©©)īó╩ŪśO╔┘öĄ(sh©┤)ĪŻAI ╣ż│╠ų«║¾Ą─ųž³c(di©Żn)Ż¼īóų▓ĮÅ─╗∙ĄA(ch©│)─Żą═Ą─ė¢(x©┤n)ŠÜ▐D(zhu©Żn)Ž“æ¬(y©®ng)ė├īėĄ─┬õĄž┼cār(ji©ż)ųĄßīĘ┼ĪŻČ° AI æ¬(y©®ng)ė├īėĄ─ā╔éĆ(g©©)ĻP(gu©Īn)µIų¦³c(di©Żn)š²╩ŪŻ║
ĪĪĪĪ·InferenceŻ©═Ų└ĒŻ®Ż║╚ń║╬ęįĖ▀ą¦ĪóĄ═│╔▒ŠĄ─ĘĮ╩Į═Ė│÷─Żą═─▄┴”;
ĪĪĪĪ·Database for ApplicationŻ©├µŽ“ AI æ¬(y©®ng)ė├Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)Ż®Ż║╚ń║╬ų¦ō╬╔ŽŽ┬╬─╣▄└ĒĪóŽ“┴┐Öz╦„ĪóöĄ(sh©┤)ō■(j©┤)š{(di©żo)ė├┼cšZ(y©│)┴x└ĒĮŌĄ╚öĄ(sh©┤)ō■(j©┤)īė─▄┴”ĪŻ
ĪĪĪĪĖ∙ō■(j©┤)├└ć°(gu©«)╩ął÷(ch©Żng)š{(di©żo)čąöĄ(sh©┤)ō■(j©┤)Ż¼ęčėą╝s 70% Ą─Ų¾śI(y©©)ęčį┌īŹ(sh©¬)ļH╔·«a(ch©Żn)śI(y©©)äš(w©┤)ųą╩╣ė├ AI ŽÓĻP(gu©Īn)Ą──▄┴”Ż¼šf(shu©Ł)├„▀@ł÷(ch©Żng)ĘČ╩Į▐D(zhu©Żn)ūāęččĖ╦┘?g©░u)─Ū░čž╝╝ąg(sh©┤)ū▀Ž“ų„┴„īŹ(sh©¬)█`ĪŻ
ĪĪĪĪ┌ģä▌(sh©¼)Č■Ż║Agent öĄ(sh©┤)┴┐┐ņ╦┘į÷ķL(zh©Żng)Ż¼öĄ(sh©┤)ō■(j©┤)Ąūū∙│╔║╦ą─ų¦ō╬
ĪĪĪĪį┌Ū░╬─╠ߥĮĄ─╚²╝ę╣½╦ŠųąŻ¼Ū░ā╔╝ęŠ∙īŻūóė┌śŗ(g©░u)Į©╗∙ė┌ PostgreSQL öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ųŪ─▄┤·└ĒŻ©AgentŻ®Ę■äš(w©┤)Ż¼Č°Ą┌╚²╝ęätŠ█Į╣ė┌═©▀^(gu©░)╠ß╣®öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ą──▄┴”×ķ AI æ¬(y©®ng)ė├╠ß╣®öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą──▄┴”ĪŻ▀@ę╗┌ģä▌(sh©¼)’@╩Š│÷Ż¼┤¾─Żą═ Agent Ą─╔·æB(t©żi)š²┐ņ╦┘Ę▒śsŻ¼▒│║¾ī”(du©¼)Ė▀ą¦ĪóĖ▀┐╔ė├Ą─öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®Ą─ąĶŪ¾ę▓į┌═¼▓Į╔²╝ē(j©¬)ĪŻ╬┤üĒ(l©ói)Ż¼Agent Ą─öĄ(sh©┤)┴┐Ģ■(hu©¼)įĮüĒ(l©ói)įĮČÓŻ¼šl(shu©¬)─▄ē“╠ß╣®šµš²▀m┼õ AI Agent Ą─öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)Ż¼īó│╔×ķ╗∙ĄA(ch©│)įO(sh©©)╩®Ėé(j©¼ng)ĀÄ(zh©źng)Ą─║╦ą─ĻP(gu©Īn)µIĪŻ
ĪĪĪĪNeon
ĪĪĪĪ╩ūŽ╚╬ęéāŽ╚üĒ(l©ói)┐┤ Neon ╩Ū╩▓├┤ĪŻ

ĪĪĪĪNeon ╩Ūę╗éĆ(g©©)╗∙ė┌ķ_(k©Īi)į┤ PostgreSQL śŗ(g©░u)Į©Ą─įŲįŁ╔·öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼╦³ū÷┴╦Äū╝■ĘŪ│ŻĻP(gu©Īn)µIĪó▀m║Žė┌ AI æ¬(y©®ng)ė├ķ_(k©Īi)░l(f©Ī)š▀Ą─╩┬ŪķŻ║
ĪĪĪĪĄ┌ę╗Ż¼╦³īóé„Įy(t©»ng)Ą─å╬ÖC(j©®)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝▄śŗ(g©░u)▐D(zhu©Żn)ūā?y©Łu)ķ┤µ╦ŃĘųļxĄ─įŲ╝▄śŗ(g©░u)ĪŻ
ĪĪĪĪ▀@ę╗³c(di©Żn)╩╣Ą├öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Š▀éõ┴╦Ė³ÅŖ(qi©óng)Ą─ÅŚąį┼c┐╔öU(ku©░)š╣ąįŻ¼ę▓×ķŲõ║¾└m(x©┤)Ą─ę╗ą®äō(chu©żng)ą┬─▄┴”┤“Ž┬┴╦╗∙ĄA(ch©│)ĪŻ
ĪĪĪĪĄ┌Č■Ż¼į┌«a(ch©Żn)ŲĘįO(sh©©)ėŗ(j©¼)╔ŽŻ¼Neon ėąā╔éĆ(g©©)ĘŪ│Ż═╗│÷Ą─┴┴³c(di©Żn)Ż║
ĪĪĪĪ·Scale to Zero(░┤ąĶÅŚąįŻ¼┐šķe╝┤ßīĘ┼)
ĪĪĪĪNeon ╣┘ŠW(w©Żng)ÅŖ(qi©óng)š{(di©żo)Ųõ║╦ą─ā×(y©Łu)ä▌(sh©¼)ų«ę╗į┌ė┌ Scale to ZeroŻ¼ę▓Š═╩Ūšf(shu©Ł)Ż¼«ö(d©Īng)─Ń▓╗╩╣ė├╦³Ģr(sh©¬)Ż¼╦³─▄ē“?q©▒)óė?j©¼)╦Ń┘Yį┤═Ļ╚½ßīĘ┼Ż¼šµš²ū÷ĄĮ“ė├ČÓ╔┘Ż¼ĖČČÓ╔┘”Ż¼▀@ī”(du©¼)ė┌┘Yį┤├¶Ėąą═æ¬(y©®ng)ė├ė╚Ųõųžę¬ĪŻ
ĪĪĪĪ·Branching(öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ęųų¦╣▄└Ē)
ĪĪĪĪ┴Ēę╗éĆ(g©©)┴┴³c(di©Żn)╩Ū Branching Ė┼─ŅĪŻŠ═Ž±╬ęéā╩╣ė├ Git ę╗śėŻ¼Neon ų¦│ų?j©½n)?sh©┤)ō■(j©┤)Äņ(k©┤)╝ē(j©¬)äeĄ─“Ęųų¦”▓┘ū„ĪŻ×ķ╩▓├┤ąĶę¬▀@éĆ(g©©)?
ĪĪĪĪę“?y©żn)ķį?AI Agent ķ_(k©Īi)░l(f©Ī)▀^(gu©░)│╠ųąŻ¼įĮüĒ(l©ói)įĮČÓĄ─ł÷(ch©Żng)Š░╔µ╝░┤¾┴┐įć“×(y©żn)ĪóČÓ╚╦ģf(xi©”)ū„Īó▓óąą╣żū„——į╩įSķ_(k©Īi)░l(f©Ī)š▀┐ņ╦┘äō(chu©żng)Į©Īó╣▄└Ē║═ŪąōQöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─¬Ü(d©▓)┴óĖ▒▒Š(Ęųų¦)Ż¼śO┤¾╠ß╔²┴╦ķ_(k©Īi)░l(f©Ī)Īó£y(c©©)įć║═öĄ(sh©┤)ō■(j©┤)╣▄└ĒĄ─ņ`╗ŅąįĪŻNeon īóöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▐D(zhu©Żn)ūā?y©Łu)ķę╗éĆ(g©©)ų¦│ų├¶Į▌ģf(xi©”)ū„Ą─ķ_(k©Īi)░l(f©Ī)ŲĮ┼_(t©ói)Ż¼×ķ AI ║═öĄ(sh©┤)ō■(j©┤)╣ż│╠┤“ķ_(k©Īi)┴╦╚½ą┬Ą─ĘČ╩ĮĪŻ
ĪĪĪĪę╗éĆ(g©©)ėą╚żĄ─ė^▓ņŻ║AI Agent š²į┌┤¾┴┐äō(chu©żng)Į©öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)
ĪĪĪĪNeon łF(tu©ón)ĻĀ(du©¼)ę▓ė^▓ņĄĮę╗éĆ(g©©)’@ų°┌ģä▌(sh©¼)Ż║AI Agent š²į┌ęįŪ░╦∙╬┤ėąĄ─╦┘Č╚äō(chu©żng)Į©öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īŹ(sh©¬)└²ĪŻ
ĪĪĪĪÅ─ 2024 ─Ļ 10 į┬ĄĮ 2025 ─Ļ 5 į┬Ż¼Č╠Č╠ 7 éĆ(g©©)į┬Ģr(sh©¬)ķgŻ¼öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)äō(chu©żng)Į©┴┐│÷¼F(xi©żn)┴╦▒¼░l(f©Ī)╩Įį÷ķL(zh©Żng)ĪŻ
ĪĪĪĪÅ─ Neon ░l(f©Ī)▓╝Ą─ų∙ĀŅłDųą┐╔ęį┐┤ĄĮŻ¼ŠG╔½▓┐Ęų┤·▒Ēė╔ AI ūįäė(d©░ng)äō(chu©żng)Į©Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ŽÓ▌^ė┌╚╦╣żäō(chu©żng)Į©Ą─īŹ(sh©¬)└²š╝▒╚’@ų°╠ß╔²Ż¼▀@šf(shu©Ł)├„ AI Agent š²į┌│╔×ķöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╩╣ė├Ą─ą┬ų„┴”Ż¼öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŲĮ┼_(t©ói)ę▓▒žĒÜ×ķ▀@ĘNą┬ą═╣żū„žō(f©┤)▌dū÷║├£╩(zh©│n)éõĪŻ

ĪĪĪĪSupabase
ĪĪĪĪSupabase ═¼śė╩Ūśŗ(g©░u)Į©į┌ PostgreSQL ų«╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŲĮ┼_(t©ói)Ż¼╦³┼c Neon śŗ(g©░u)│╔┴╦ų▒ĮėĄ─Ėé(j©¼ng)ĀÄ(zh©źng)ĻP(gu©Īn)ŽĄĪŻĄ½┼c Neon ŽÓ▒╚Ż¼Supabase ╠ß╣®┴╦Ė³×ķžSĖ╗Ą─╣”─▄╝»Ż¼░³└©╔ĒĘ▌“×(y©żn)ūCĪóī”(du©¼)Ž¾┤µā”(ch©│)ĪóīŹ(sh©¬)Ģr(sh©¬)ėåķåĪó▀ģŠē║»öĄ(sh©┤)Ą╚Ę■äš(w©┤)Ż¼Äū║§┐╔ęį┐┤ū„╩Ū“ķ_(k©Īi)į┤░µĄ─ Firebase”Ż¼Č©╬╗×ķķ_(k©Īi)░l(f©Ī)š▀Ą─ę╗šŠ╩Į║¾Č╦Ę■äš(w©┤)ŲĮ┼_(t©ói)ĪŻ

ĪĪĪĪ×ķ╩▓├┤▀@ą®╣½╦Šį┌ūŅĮ³éõ╩▄ĻP(gu©Īn)ūó?
ĪĪĪĪ▀@▒│║¾ėąę╗éĆ(g©©)ĘŪ│ŻŪÕ╬·Ą─┌ģä▌(sh©¼)┼ąöÓŻ║┤¾─Żą═ė¢(x©┤n)ŠÜĄ─╝t└¹Ų┌š²į┌ĮėĮ³╬▓┬ĢĪŻļm╚╗śI(y©©)Įń╔ą╬┤š²╩Įą¹▓╝“ė¢(x©┤n)ŠÜĢr(sh©¬)┤·”Ą─ĮKĮY(ji©”)Ż¼Ą½Å─┘Y▒Š║═╝╝ąg(sh©┤)äė(d©░ng)Ž“üĒ(l©ói)┐┤Ż¼╬┤üĒ(l©ói)į┘╚ź═Č┘Yą┬Ą─╗∙ĄA(ch©│)─Żą═╣½╦Šęč▓╗į┘╩Ūų„┴„ĪŻŽÓĘ┤Ż¼╦∙ėą╚╦Ą─ūóęŌ┴”Č╝į┌Ž““æ¬(y©®ng)ė├īė”Š█Į╣——▀@Š═╩Ū╬ęéāė^▓ņĄĮĄ─Ą┌ę╗éĆ(g©©)ųžę¬¼F(xi©żn)Ž¾Ż║
ĪĪĪĪInferenceŻ©═Ų└ĒŻ®║═öĄ(sh©┤)ō■(j©┤)æ¬(y©®ng)ė├š²į┌│╔×ķą┬Į╣³c(di©Żn)ĪŻ
ĪĪĪĪ¤o(w©▓)šō╩Ū NeonĪóSupabaseŻ¼▀Ć╩ŪŲõ╦¹ą┬┼dĄ─öĄ(sh©┤)ō■(j©┤)╗∙ĄA(ch©│)įO(sh©©)╩®ĒŚ(xi©żng)─┐Ż¼▒Š┘|(zh©¼)╔ŽČ╝į┌ć·└@▀@éĆ(g©©)┌ģä▌(sh©¼)▀M(j©¼n)ąą▓╝ŠųĪŻ
ĪĪĪĪPostgreSQLŻ║ą┬┼döĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─╣▓ūR(sh©¬)╗∙╩»
ĪĪĪĪÄū║§╦∙ėąĄ─ą┬ą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĒŚ(xi©żng)─┐Č╝▀xō±╗∙ė┌ PostgreSQL śŗ(g©░u)Į©ĪŻ╬ęéāäé▓┼╠ߥĮĄ─ Neon ║═ Supabase ų╗╩ŪŲõųąĄ─ā╔éĆ(g©©)┤·▒ĒŻ¼īŹ(sh©¬)ļH╔ŽŻ¼╚½Ū“Į³Äū─Ļą┬│÷¼F(xi©żn)Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)«a(ch©Żn)ŲĘŻ¼CockroachDBŻ¼YugabyteDBŻ¼║═ DuckDB ę▓Č╝¤o(w©▓)ę╗└²═ŌĄ─▀xō±┴╦ PostgreSQL ū„×ķ▓ķįā APIĪŻ
ĪĪĪĪPostgreSQL ┐┐ŲõÅŖ(qi©óng)┤¾Ą─┐╔öU(ku©░)š╣ąį║═╔·æB(t©żi)Ż¼┌AĄ├┴╦╚½Ū“╦∙ėąą┬┼döĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ŪÓ▓AĪŻ
ĪĪĪĪ×ķ╩▓├┤ PostgreSQL Ģ■(hu©¼)│╔×ķ╩┬īŹ(sh©¬)╔ŽĄ─ąąśI(y©©)ś╦(bi©Īo)£╩(zh©│n)Ż┐
ĪĪĪĪįŁę“║▄║å(ji©Żn)å╬Ż║
ĪĪĪĪ·PostgreSQL ĘŪ│Żś╦(bi©Īo)£╩(zh©│n)║═ęÄ(gu©®)ĘČŻ¼│²┴╦ SQL ▒Š╔ĒŠ═Ė▓╔w┴╦ OLTP ║═ OLAP Ą─ąĶŪ¾═ŌŻ¼ŲõūŅ┤¾Ą─ā×(y©Łu)³c(di©Żn)Š═╩ŪėąÅŖ(qi©óng)┤¾Ą─┐╔öU(ku©░)š╣ąįĪŻ╦³į╩įSė├æ¶═©▀^(gu©░)öU(ku©░)š╣Ż©ExtensionsŻ®üĒ(l©ói)į÷ÅŖ(qi©óng)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╣”─▄Ż©╚½╬─Öz╦„Ż¼Ž“┴┐Öz╦„Ż¼Ąž└Ēą┼ŽóÖz╦„Ż¼Ģr(sh©¬)ą“╠Ä└ĒĄ╚Ą╚Ż®Ż¼Č°¤o(w©▓)ąĶą▐Ė─║╦ą─┤·┤aĪŻ
ĪĪĪĪ·PostgreSQL ęčą╬│╔ÅŖ(qi©óng)┤¾Ą─╔ńģ^(q©▒)╔·æB(t©żi)║═╣żŠ▀ų¦│ųĪŻ
ĪĪĪĪęįŽ“┴┐Öz╦„×ķ└²Ż║
ĪĪĪĪPostgreSQL ╠ß╣®┴╦įŁ╔·Ą─pgvector öU(ku©░)š╣Ż¼┐╔ęįų▒Įėų¦│ųŽ“┴┐öĄ(sh©┤)ō■(j©┤)Ą─┤µā”(ch©│)┼cÖz╦„;Č°į┌ MySQL ś╦(bi©Īo)£╩(zh©│n)ųąŻ¼╚▒Ę”┐╔öU(ku©░)š╣ąįĮė┐┌┼c╔·æB(t©żi)Ż¼MySQL öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)═∙═∙ąĶę¬ūįąąČ©┴xŽ“┴┐öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)║═Öz╦„Ą─ APIŻ¼ī¦(d©Żo)ų┬īŹ(sh©¬)¼F(xi©żn)Ū¦▓Ņ╚f(w©żn)äeŻ¼╚▒Ę”ś╦(bi©Īo)£╩(zh©│n)ĪŻ▀@ę▓╩Ū×ķ╩▓├┤įĮüĒ(l©ói)įĮČÓĄ─ AI ╣½╦ŠŻ¼╠žäe╩Ū OpenAIĪóAnthropicĪóNotion Ą╚┤¾ą═ AI │§äō(chu©żng)ĒŚ(xi©żng)─┐Ż¼Č╝▀xō± PostgreSQL ū„×ķŲõ║╦ą─öĄ(sh©┤)ō■(j©┤)ę²ŪµĪŻ
ĪĪĪĪ╬ęį°┐┤ĄĮę╗ätĘŪ╣┘ĘĮĄ─ł¾(b©żo)Ą└Ż║OpenAI ā╚(n©©i)▓┐Ą─ę╗éĆ(g©©) PostgreSQL ų╗ūxÅ─Äņ(k©┤)Š═▓┐╩┴╦Į³ 50 éĆ(g©©)īŹ(sh©¬)└²ĪŻ ļm╚╗─┐Ū░ OpenAI ╔ą╬┤▓╔ė├Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝▄śŗ(g©░u)Ż¼Ą½ļSų°śI(y©©)äš(w©┤)ęÄ(gu©®)─ŻĄ─│ų└m(x©┤)öU(ku©░)ÅłŻ¼▀@╗“?q©▒)ó│╔×ķŲõ╬┤ü?l©ói)▒žĒÜæ¬(y©®ng)ī”(du©¼)Ą─╝▄śŗ(g©░u)╠¶æ(zh©żn)ĪŻ
ĪĪĪĪAgent Talk to MCPŻ║PostgreSQL ╩Ū─¼šJ(r©©n)▀xĒŚ(xi©żng)ų«ę╗
ĪĪĪĪ╬ę╝┤īóĮķĮBĄ─ę╗éĆ(g©©)Ė┼─Ņ╩Ū“Agent Talk to MCP(Model Context Protocol)”ĪŻ▀@éĆ(g©©)Ė┼─ŅūŅįńė╔ Anthropic ╠ß│÷Ż¼Č°į┌Ųõ╣┘ĘĮ╬─ÖnųąŻ¼├„┤_┴ą│÷Ą─Ą┌Č■éĆ(g©©)ų¦│ųŲĮ┼_(t©ói)Š═╩Ū PostgreSQLĪŻ
ĪĪĪĪ▀@▀M(j©¼n)ę╗▓ĮėĪūC┴╦ PostgreSQL į┌ AI æ¬(y©®ng)ė├╣żū„žō(f©┤)▌dųąĄ─ĻP(gu©Īn)µIū„ė├——╦³▓╗āH╩Ūę╗ĘNöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼Ė³╩Ū AI ŽĄĮy(t©»ng)┼cöĄ(sh©┤)ō■(j©┤)Į╗╗źĄ─ųąśąŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪClickHouse Ą─Č©╬╗č▌ūā┼cČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ß╚Ų
ĪĪĪĪŽÓ▒╚ Neon ║═ SupabaseŻ¼ClickHouse Ą─Č©╬╗ŲõīŹ(sh©¬)ėą╦∙▓╗═¼ĪŻ╦³▒Š┘|(zh©¼)╔Ž╩Ūę╗┐ŅöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ĪŻ┤╦Ū░Ż¼į┌╦³Ą─ČÓ▌åī”(du©¼)═Ōą¹é„ųąŻ¼ę╗ų▒ÅŖ(qi©óng)š{(di©żo)ūį╔Ē╩Ūę╗éĆ(g©©) Real-time Data Warehouse(īŹ(sh©¬)Ģr(sh©¬)öĄ(sh©┤)é}(c©Īng))ĪŻĄ½ūŅĮ³╬ęį┘┤╬┤“ķ_(k©Īi) ClickHouse Ą─╣┘ŠW(w©Żng)Ż¼░l(f©Ī)¼F(xi©żn)╦³ę▓ķ_(k©Īi)╩╝ĘQūį╝║×ķ Database(öĄ(sh©┤)ō■(j©┤)Äņ(k©┤))┴╦(ClickHouse ┤_īŹ(sh©¬)ę╗ų▒į┌ķ_(k©Īi)░l(f©Ī) OLTP Ą──▄┴”Ż¼ų╗╩Ūę╗ų▒▀Ćø](m©”i)ėąš²╩Į░l(f©Ī)▓╝)ĪŻ▀@▒│║¾Ę┤ė││÷ę╗éĆ(g©©)┌ģä▌(sh©¼)Ż║╬┤üĒ(l©ói) AI æ¬(y©®ng)ė├īėīóįĮüĒ(l©ói)įĮę└┘ćöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ė╚Ųõ╩ŪČÓ─ŻæB(t©żi)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)īó│╔×ķ║╦ą─╗∙ĄA(ch©│)įO(sh©©)╩®ĪŻ

ĪĪĪĪ┼eéĆ(g©©)└²ūėŻ║
ĪĪĪĪ·╚ń╣¹─Ńš²į┌ķ_(k©Īi)░l(f©Ī)ę╗éĆ(g©©)╗∙ė┌ AI Ą─ AgentŻ¼╦³ä▌(sh©¼)▒žąĶę¬┼cĖ„ĘNöĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)║═æ¬(y©®ng)ė├ŽĄĮy(t©»ng)Į╗╗źĪŻ░┤ššé„Įy(t©»ng)╝▄śŗ(g©░u)Ą─Ęų╣ż─Ż╩ĮŻ║╩┬äš(w©┤)ąįöĄ(sh©┤)ō■(j©┤)Ę┼į┌ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ųą;
ĪĪĪĪ·öĄ(sh©┤)ō■(j©┤)Ą─ÖMŽ“╦«ŲĮĘų▓╝╩ĮöU(ku©░)š╣ė├ MongoDB ╗“ HBase;
ĪĪĪĪ·╦č╦„╣”─▄ė├ Elasticsearch(ES)īŹ(sh©¬)¼F(xi©żn);
ĪĪĪĪ·Ęų╬÷ąĶŪ¾ė├ ClickHouse ų¦ō╬;
ĪĪĪĪ▀@ęŌ╬Čų°Ż¼ę╗éĆ(g©©)Ų¾śI(y©©)āHį┌öĄ(sh©┤)ō■(j©┤)ĄūīėŠ═ꬊSūo(h©┤)ų┴╔┘ 4 éĆ(g©©)▓╗═¼Ą─ MCP(Model Context Protocol )Ę■äš(w©┤)ĪŻ▀@ī”(du©¼)┤¾─Żą═üĒ(l©ói)šf(shu©Ł)╩ŪéĆ(g©©)Š▐┤¾Ą─╠¶æ(zh©żn)ĪŻ└Ēšō╔Ž╦³┐╔ęį└ĒĮŌ▀@ą®▓Ņ«É╗»Ą─Ę■äš(w©┤)Ż¼Ą½īŹ(sh©¬)ļH▀\(y©┤n)ū„ųąĘŪ│ŻÅ═(f©┤)ļsŻ¼ī”(du©¼)Ųõ“ųŪ┴””śŗ(g©░u)│╔Ė▀ÅŖ(qi©óng)Č╚žō(f©┤)║╔ĪŻ─▄ī”(du©¼)Įėę╗éĆ(g©©) MCPŻ¼šl(shu©¬)▀Ćę¬ī”(du©¼)Įė 4 éĆ(g©©)─ž?▀@ę▓š²╩Ū×ķ╩▓├┤įĮüĒ(l©ói)įĮČÓĄ─ AI │§äō(chu©żng)╣½╦Š▀xō± PostgreSQLŻ¼Č°╬┤üĒ(l©ói)┤¾ą═Ų¾śI(y©©)į┌├µŽ“ AI ł÷(ch©Żng)Š░▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▀xą═Ģr(sh©¬)Ż¼ę▓ę╗Č©Ģ■(hu©¼)āAŽ“▀xō±ų¦│ųČÓ─ŻæB(t©żi)Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŲĮ┼_(t©ói)ĪŻ
ĪĪĪĪļm╚╗╬ęéāäé▓┼╠ߥĮė¢(x©┤n)ŠÜĄ─Ģr(sh©¬)┤·ĮėĮ³╬▓┬ĢŻ¼Ą½ė¢(x©┤n)ŠÜ▒Š╔ĒĄ─å¢(w©©n)Ņ}ę└╚╗┤µį┌Ż¼ė╚Ųõ╩Ūį┌┤µā”(ch©│)īė├µĪŻ╬ęéā?c©©)°ėąę╗ŠõąąśI(y©©)╣▓ūR(sh©¬)Ż║“AI Ą─Ų┐Ņiį┌ėŗ(j©¼)╦ŃŻ¼ėŗ(j©¼)╦ŃĄ─Ų┐Ņiį┌┤µā”(ch©│)ĪŻ”▀@ŠõįÆų„ę¬╩Ūßśī”(du©¼)─Żą═ė¢(x©┤n)ŠÜļAČ╬Č°čįĄ─ĪŻČ°╬ęéāęį║¾Ė³ĻP(gu©Īn)ūóĄ─īó╩ŪAI æ¬(y©®ng)ė├║═ Workflow Ą─ł╠(zh©¬)ąąą¦┬╩ĪŻ
ĪĪĪĪ«ö(d©Īng)Ū░Ż¼┤¾─Żą═▓ó▓╗─▄═Ļ╚½╠µė├涚¹└Ē║├╦∙ėąöĄ(sh©┤)ō■(j©┤)Ż¼┼õ║Ž┤¾─Żą═ę╗Ų╣żū„Ą─ AI workflow ų„ę¬╝»ųąį┌╦─éĆ(g©©)ĻP(gu©Īn)µIŁh(hu©ón)╣Ø(ji©”)Ż║
ĪĪĪĪ·IngestionŻ©öĄ(sh©┤)ō■(j©┤)öz╚ĪŻ®
ĪĪĪĪ·TransformŻ©öĄ(sh©┤)ō■(j©┤)╝ė╣żŻ®
ĪĪĪĪ·ExploreŻ©╠Į╦„Ęų╬÷Ż®
ĪĪĪĪ·RetrieveŻ©▓ķįāÖz╦„Ż®
ĪĪĪĪė¢(x©┤n)ŠÜĄ─Ų┐Ņi╚į╚╗┤µį┌Ż¼Ą½ųž³c(di©Żn)š²į┌▐D(zhu©Żn)Ž“ AI æ¬(y©®ng)ė├┴„│╠Ż©AI WorkflowŻ®
ĪĪĪĪļm╚╗╬ęéāäé▓┼╠ߥĮė¢(x©┤n)ŠÜĄ─Ģr(sh©¬)┤·ĮėĮ³╬▓┬ĢŻ¼Ą½ė¢(x©┤n)ŠÜ▒Š╔ĒĄ─å¢(w©©n)Ņ}ę└╚╗┤µį┌Ż¼ė╚Ųõ╩Ūį┌┤µā”(ch©│)īė├µĪŻ╬ęéā?c©©)°ėąę╗ŠõąąśI(y©©)╣▓ūR(sh©¬)Ż║“AI Ą─Ų┐Ņiį┌ėŗ(j©¼)╦ŃŻ¼ėŗ(j©¼)╦ŃĄ─Ų┐Ņiį┌┤µā”(ch©│)ĪŻ”▀@ŠõįÆų„ę¬╩Ūßśī”(du©¼)ė¢(x©┤n)ŠÜļAČ╬Č°čįĄ─ĪŻČ°╬ęéā¼F(xi©żn)į┌Ė³ĻP(gu©Īn)ūóĄ─╩Ū AI æ¬(y©®ng)ė├║═ Workflow Ą─ł╠(zh©¬)ąąą¦┬╩ĪŻ
ĪĪĪĪ«ö(d©Īng)Ū░Ż¼┤¾─Żą═▓ó▓╗─▄═Ļ╚½╠µ─Ńš¹└Ē║├╦∙ėąöĄ(sh©┤)ō■(j©┤)Ż¼ė╚Ųõį┌šµīŹ(sh©¬)╔·«a(ch©Żn)Łh(hu©ón)Š│ųąŻ¼╦³ę▓▓╗Ģ■(hu©¼)ūįäė(d©░ng)äō(chu©żng)Į©öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪŻ╦³─▄ū÷Ą─Ż¼ų„ę¬╝»ųąį┌╬ęéāŪ░├µ╠ߥĮĄ─╦─éĆ(g©©)ĻP(gu©Īn)µIŁh(hu©ón)╣Ø(ji©”)Ż║
ĪĪĪĪ·IngestionŻ©öĄ(sh©┤)ō■(j©┤)öz╚ĪŻ®
ĪĪĪĪ·TransformŻ©öĄ(sh©┤)ō■(j©┤)╝ė╣żŻ®
ĪĪĪĪ·ExploreŻ©╠Į╦„Ęų╬÷Ż®
ĪĪĪĪ·RetrieveŻ©▓ķįāÖz╦„Ż®

ĪĪĪĪAI workflow Å─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Īóæ¬(y©®ng)ė├╚šųŠĪó┬±³c(di©Żn)ŽĄĮy(t©»ng)Ą╚üĒ(l©ói)į┤╩š╝»öĄ(sh©┤)ō■(j©┤);ļS║¾═©▀^(gu©░)öĄ(sh©┤)ō■(j©┤)ŪÕŽ┤┼c▐D(zhu©Żn)ōQ▀M(j©¼n)ąą╝ė╣ż;╝ė╣ż║¾Ą─öĄ(sh©┤)ō■(j©┤)┐╔─▄▀M(j©¼n)╚ļ Feature StoreŻ¼╚╗║¾ė╔öĄ(sh©┤)ō■(j©┤)╣ż│╠Ĥ╗“╦ŃĘ©īŻ╝ę▀M(j©¼n)ąą╠Į╦„┼cĘų╬÷Ż¼ū÷│÷ģóöĄ(sh©┤)š{(di©żo)š¹Ą╚ĻP(gu©Īn)µIøQ▓▀ĪŻ«ö(d©Īng)▀@ą®öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ│õĘų║¾Ż¼ĮY(ji©”)║Ž┤¾─Żą═Ą──▄┴”Ż¼▒Ń┐╔īŹ(sh©¬)¼F(xi©żn)Ž┬ę╗ļAČ╬Ą─ųžę¬─▄┴”ĪŻ
ĪĪĪĪMulti-Modal RetrievalŻ║Ž┬ę╗┤·ųŪ─▄Öz╦„ĘČ╩Į
ĪĪĪĪ╩▓├┤╩Ū Multi-Modal RetrievalŻ┐ ╦³Ą─║╦ą─║¼┴x╩ŪŻ║į┌öĄ(sh©┤)ō■(j©┤)Öz╦„▀^(gu©░)│╠ųąŻ¼▓╗į┘ŠųŽ▐ė┌─│ę╗ĘN▓ķįāĘĮ╩ĮŻ¼Č°╩Ū╚┌║ŽĮY(ji©”)śŗ(g©░u)╗»Īó░ļĮY(ji©”)śŗ(g©░u)╗»ĪóĘŪĮY(ji©”)śŗ(g©░u)╗»ęį╝░Ž“┴┐Öz╦„Ą╚ČÓĘNĘĮ╩ĮŻ¼īŹ(sh©¬)¼F(xi©żn)Ė³ųŪ─▄ĪóĖ³╚½├µĄ─▓ķįā¾w“×(y©żn)ĪŻ▀@ĒŚ(xi©żng)─▄┴”ī”(du©¼)ė┌ AI æ¬(y©®ng)ė├ė╚Ųõųžę¬ĪŻę“?y©żn)?Agent ├µī”(du©¼)Ą─å¢(w©©n)Ņ}═∙═∙▓╗╩Ū“▓ķę╗Ślą┼Žó╗“š▀ę╗éĆ(g©©)Ž“┴┐”Ż¼Č°╩ŪąĶę¬ī”(du©¼)ČÓéĆ(g©©)─ŻæB(t©żi)ĪóČÓŠSöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą└ĒĮŌĪóĻP(gu©Īn)┬ō(li©ón)║═š{(di©żo)ė├——▀@Š═ąĶꬥūīėöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Š▀éõįŁ╔·Ą─ČÓ─Ż╠Ä└Ē─▄┴”ĪŻ
ĪĪĪĪęį“ųŪ─▄│Ū╩ą”×ķ└²Ż¼╚ń╣¹╬ęéāąĶę¬į┌▒O(ji©Īn)┐žŽĄĮy(t©»ng)ųą╦č╦„─│▌v▄ć(ch©ź)╗“─│éĆ(g©©)╚╦Ż¼ūŅ╗∙ĄA(ch©│)Ą─ĘĮ╩Į┐╔─▄āH╔µ╝░Ž“┴┐Öz╦„——▒╚╚ń═©▀^(gu©░)łDŲ¼╗“ęĢŅlļ▀M(j©¼n)ąąŽÓ╦ŲČ╚Ųź┼õĪŻĄ½ę╗Ą®╬ęéāę²╚ļĖ³Š▀¾wĄ─▓ķįāŚl╝■Ż¼▒╚╚ń“─│éĆ(g©©)╩«ūų┬Ę┐┌”“─│éĆ(g©©)Ž┬ėĻ╠ņ”“─│éĆ(g©©)Ģr(sh©¬)ķgČ╬”Ż¼“║═─│éĆ(g©©)▄ć(ch©ź)Ą─łDŲ¼ŽÓ╦Ų”Ą─ł÷(ch©Żng)Š░Š═Ģ■(hu©¼)╔µ╝░ĄĮĖ³ČÓ─ŻæB(t©żi)Ą─ą┼ŽóŻ║
ĪĪĪĪ·“╩«ūų┬Ę┐┌”╩Ū╬╗ų├ś╦(bi©Īo)║×;
ĪĪĪĪ·“Ž┬ėĻ╠ņ”╩ŪŁh(hu©ón)Š│ś╦(bi©Īo)║×;
ĪĪĪĪ·“Ģr(sh©¬)ķgČ╬”╩ŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤);
ĪĪĪĪ·“▄ć(ch©ź)Ą─łDŲ¼”Ģ■(hu©¼)▒╗ embedding │╔Ž“┴┐öĄ(sh©┤)ō■(j©┤);
ĪĪĪĪ▀@ŅÉ▓ķįāŠ═▓╗į┘╩Ūå╬ę╗─ŻæB(t©żi)Ą─Öz╦„Ż¼Č°╩ŪąĶę¬═¼Ģr(sh©¬)╚┌║ŽĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤) + ś╦(bi©Īo)║׹┼Žó + Ž“┴┐Öz╦„Ą─ Multi-Modal RetrievalŻ©ČÓ─ŻæB(t©żi)Öz╦„Ż®ĪŻ
ĪĪĪĪį┘▒╚╚ńį┌╔ńĮ╗═Ų╦]ł÷(ch©Żng)Š░ųąŻ¼╚╦┼c╚╦ų«ķgĄ─═Ų╦]┐╔─▄═©▀^(gu©░) Embedding ┤¾▓┐Ęų╠žš„│╔×ķŽ“┴┐Ż¼į┘┐┐Ž“┴┐ŽÓ╦ŲČ╚Öz╦„üĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)ĪŻĄ½╚ń╣¹ė├æ¶╠Ē╝ė┴╦“═¼ę╗éĆ(g©©)│Ū╩ą”╗““═¼ę╗╗Ņäė(d©░ng)”Ą─▀^(gu©░)×VŚl╝■Ż¼Š═ę²╚ļ┴╦Ąž└Ē╬╗ų├╗“╩┬╝■ś╦(bi©Īo)║ׯ¼Å─Č°╔²╝ē(j©¬)×ķšµš²Ą─ČÓ─ŻæB(t©żi)Öz╦„╚╬äš(w©┤)ĪŻ
ĪĪĪĪČÓ─ŻæB(t©żi)Öz╦„ī”(du©¼)╝▄śŗ(g©░u)╠ß│÷┴╦Ė³Ė▀ę¬Ū¾
ĪĪĪĪīŹ(sh©¬)¼F(xi©żn) Multi-Modal RetrievalŻ¼ęŌ╬Čų°ŽĄĮy(t©»ng)▒žĒÜ═¼Ģr(sh©¬)╠Ä└ĒŻ║
ĪĪĪĪ·ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ż╗
ĪĪĪĪ·░ļĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ż©╚ń JSONŻ®Ż╗
ĪĪĪĪ·Ž“┴┐öĄ(sh©┤)ō■(j©┤)ĪŻ
ĪĪĪĪį┌é„Įy(t©»ng)╝▄śŗ(g©░u)ųąŻ¼▓╗═¼ŅÉą═Ą─öĄ(sh©┤)ō■(j©┤)═∙═∙▒╗┤µā”(ch©│)į┌▓╗═¼Ą─ŽĄĮy(t©»ng)ųąŻ║
ĪĪĪĪ·ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)ė├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╗“öĄ(sh©┤)é}(c©Īng);
ĪĪĪĪ·░ļĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─┤µā”(ch©│)║═Öz╦„ė├ NoSQL;
ĪĪĪĪ·Ž“┴┐Öz╦„ė├Ž“┴┐öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪŻ
ĪĪĪĪ▀@śėĄ─å¢(w©©n)Ņ}╩Ū«ö(d©Īng)╬ęéāꬳ╠(zh©¬)ąąę╗éĆ(g©©) Top 100 ═Ų╦]╚╬äš(w©┤)Ģr(sh©¬)Ż¼Ęų▓╝į┌ČÓéĆ(g©©)ŽĄĮy(t©»ng)ųąĄ─ĮY(ji©”)╣¹║▄ļyų▒Įė▀M(j©¼n)ąą Join ▓┘ū„Ż¼ę“?y©żn)ķąį─▄║▄▓ŅĪŻė┌╩ŪŻ¼╬ęéāų╗─▄ć(ch©ź)LįćÅ─├┐éĆ(g©©)ŽĄĮy(t©»ng)ųą╠ß╚Ī┤¾┴┐ĮY(ji©”)╣¹(╚ń Top 100 ╚f(w©żn))Ż¼į┘į┌æ¬(y©®ng)ė├īė║Ž▓óĻP(gu©Īn)┬ō(li©ón)╠Ä└ĒĪŻ▀@éĆ(g©©)▀^(gu©░)│╠▓╗āHķ_(k©Īi)õN(xi©Īo)śO┤¾Ż¼Č°Ūęę▓Å─└Ēšō╔Ž¤o(w©▓)Ę©▒ŻšŽ─├ĄĮūŅ║¾š²┤_Ą─ Top 100ĪŻ▀@š²╩Ū Hybrid DatabaseŻ©╗ņ║Žą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż®ĄŪł÷(ch©Żng)Ą─└Ēė╔Ż║
ĪĪĪĪīóČÓĘN─ŻæB(t©żi)öĄ(sh©┤)ō■(j©┤)Įy(t©»ng)ę╗┤µā”(ch©│)┼cÖz╦„Ż¼Ž¹│²ŽĄĮy(t©»ng)ķgĄ─ĘųĖŅŻ¼ūīČÓ─ŻæB(t©żi)▓ķįāūāĄ├ūį╚╗ĪóīŹ(sh©¬)Ģr(sh©¬)Ūę┐╔öU(ku©░)š╣ĪŻ
ĪĪĪĪAI Workflow Ą─╬ÕéĆ(g©©)ĻP(gu©Īn)µIąĶŪ¾
ĪĪĪĪ×ķ┴╦ų¦ō╬šµš²Ą─ AI ╣żū„┴„Ż¼Å─öĄ(sh©┤)ō■(j©┤)½@╚ĪĄĮĮY(ji©”)╣¹Į╗ĖČŻ¼ŽĄĮy(t©»ng)▒žĒÜØMūŃęįŽ┬╬Õ┤¾║╦ą──▄┴”Ż║
ĪĪĪĪ1.Fresh DataŻ©öĄ(sh©┤)ō■(j©┤)ą┬§rąįŻ® ─Żą═▒žĒÜ╗∙ė┌ūŅą┬Ą─öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąą═Ų└ĒŻ¼öĄ(sh©┤)ō■(j©┤)£■║¾īóć└(y©ón)ųžė░Ēæ AI «a(ch©Żn)│÷┘|(zh©¼)┴┐ĪŻ
ĪĪĪĪ2.Instant RetrievalŻ©╝┤Ģr(sh©¬)Öz╦„Ż®ąĶę¬║┴├ļ╝ē(j©¬)Ą─öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)─▄┴”Ż¼ęįØMūŃīŹ(sh©¬)Ģr(sh©¬)Ēææ¬(y©®ng)║══Ų╦]ąĶŪ¾ĪŻ
ĪĪĪĪ3.High ConcurrencyŻ©Ė▀▓ó░l(f©Ī)Ż®╠žäe╩Ūį┌├µŽ“ C Č╦╗“ Agent ł÷(ch©Żng)Š░ųąŻ¼ŽĄĮy(t©»ng)ąĶ─▄ų¦ō╬│╔Ū¦╔Ž╚f(w©żn)ė├æ¶═¼Ģr(sh©¬)įLå¢(w©©n)Ż¼Š▀éõĖ▀═╠═┬─▄┴”ĪŻ
ĪĪĪĪ4.Fast AnalyticsŻ©┐ņ╦┘Ęų╬÷Ż®▓╗āHę¬─▄┤µā”(ch©│)öĄ(sh©┤)ō■(j©┤)Ż¼▀Ćę¬─▄┐ņ╦┘═Ļ│╔Š█║ŽĪó▀^(gu©░)×VĪó┼┼ą“Ą╚Ęų╬÷╚╬äš(w©┤)Ż¼×ķ AI øQ▓▀╠ß╣®ų¦│ųĪŻ
ĪĪĪĪ5.SimplicityŻ©ęūė├ąįŻ®š¹éĆ(g©©)ŽĄĮy(t©»ng)ꬊ▀éõ┴╝║├Ą─ķ_(k©Īi)░l(f©Ī)š▀¾w“×(y©żn)║═╣▄└Ē║å(ji©Żn)ØŹąįŻ¼▒▄├ŌČÓ╣żŠ▀µ£ĪóČÓŲĮ┼_(t©ói)ŪąōQĦüĒ(l©ói)Ą─Å═(f©┤)ļsąįĪŻ
ĪĪĪĪ▀@ą®─▄┴”śŗ(g©░u)│╔┴╦¼F(xi©żn)┤· AI æ¬(y©®ng)ė├╣żū„┴„Ą─╗∙ĄA(ch©│)▒ŻšŽĪŻų╗ėąśŗ(g©░u)Į©ę╗éĆ(g©©)ØMūŃīŹ(sh©¬)Ģr(sh©¬)ąįĪó╚┌║ŽąįĪóĖ▀▓ó░l(f©Ī)┼cęūė├ąįĄ─öĄ(sh©┤)ō■(j©┤)ŲĮ┼_(t©ói)Ż¼▓┼─▄šµš²ßīĘ┼┤¾─Żą═║═ Agent Ą─ųŪ─▄Øō┴”ĪŻ

ĪĪĪĪ×ķ╩▓├┤é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)║═öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ļyęįØMūŃ AI Workflow Ą─╚½▓┐ąĶŪ¾Ż┐
ĪĪĪĪŪ░├µ╠ߥĮĄ──Ūą®«a(ch©Żn)ŲĘų«╦∙ęįéõ╩▄ÜgėŁŻ¼▒Š┘|(zh©¼)╔Ž╩Ū╦³éāĖ„ūįĮŌøQ┴╦ AI ╣żū„┴„ųąĄ─ĻP(gu©Īn)µI═┤³c(di©Żn)Ż¼Ą½╚į┤µį┌├„’@ŠųŽ▐Ż║
ĪĪĪĪ·öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż║╔├ķL(zh©Żng)╠Ä└Ē Fresh Data(öĄ(sh©┤)ō■(j©┤)ą┬§rąį) ║═ Instant Retrieval(╝┤Ģr(sh©¬)Öz╦„)Ż¼▀mė├ė┌īŹ(sh©¬)Ģr(sh©¬)īæ(xi©¦)╚ļ║═┐ņ╦┘▓ķįāł÷(ch©Żng)Š░ĪŻĄ½Ųõ┤¾ČÓ╗∙ė┌å╬ÖC(j©®)╗“║å(ji©Żn)å╬ų„Å─╝▄śŗ(g©░u)Ż¼ļyęįų¦ō╬┤¾ęÄ(gu©®)─ŻĄ─Ė▀▓ó░l(f©Ī)įLå¢(w©©n)ĪŻ
ĪĪĪĪ·öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ż©╚ń ClickHouseŻ®Ż║į┌ Ęų╬÷ąį─▄(Fast Analytics) ║═ ╩╣ė├║å(ji©Żn)ØŹąį(Simplicity) ĘĮ├µ▒Ē¼F(xi©żn)│÷╔½Ż¼Ą½╦³éāŲš▒ķ▓╗▀m║ŽĖ▀Ņlīæ(xi©¦)╚ļ╗“Ą═čė▀tĒææ¬(y©®ng)ł÷(ch©Żng)Š░ĪŻ
ĪĪĪĪōQŠõįÆšf(shu©Ł)Ż¼ø](m©”i)ėąę╗éĆ(g©©)ŽĄĮy(t©»ng)─▄ē“═¼Ģr(sh©¬)╝µŅÖ AI æ¬(y©®ng)ė├Ą─╬Õ┤¾ĻP(gu©Īn)µIįVŪ¾ĪŻ

ĪĪĪĪIntroducing Data Warebase Ż║╩▓├┤╩Ū Data Warebase
ĪĪĪĪę“┤╦Ż¼╬ęéā╠ß│÷┴╦ Data Warebase Ą─Ė┼─Ņ——īó Data Warehouse ┼c Database ╚┌║Žė┌ę╗¾wŻ¼śŗ(g©░u)Į©Įy(t©»ng)ę╗Ą─öĄ(sh©┤)ō■(j©┤)Ąūū∙Ż¼ęį╚½├µų¦ō╬ AI ╣żū„┴„ųąÅ─öĄ(sh©┤)ō■(j©┤)▓╔╝»Īó╝ė╣żĪóĘų╬÷ĄĮÖz╦„Ą─╚½▀^(gu©░)│╠ĪŻ
ĪĪĪĪĖ∙ō■(j©┤)╬ęéāŪ░╬─Ą─╝▄śŗ(g©░u)─Żą═Ż¼╚╬║╬ę╗╝ę╣½╦Šį┌śŗ(g©░u)Į©öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)Ģr(sh©¬)Ż¼Č╝Ģ■(hu©¼)├µ┼R╚ńŽ┬ÄūŅÉ║╦ą─ąĶŪ¾Ż║
ĪĪĪĪ·╩┬äš(w©┤)ą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż║ė├ė┌īŹ(sh©¬)Ģr(sh©¬)īæ(xi©¦)╚ļ┼c▓ķįā(╚ńėåå╬Īóąą×ķ╚šųŠ)
ĪĪĪĪ·╬─▒Š╦č╦„ę²ŪµŻ║╠Ä└ĒĘŪĮY(ji©”)śŗ(g©░u)╗»ĻP(gu©Īn)µIį~Ųź┼õ(╚ń╚½╬─╦č╦„)
ĪĪĪĪ·Ž“┴┐╦č╦„ę²ŪµŻ║ų¦ō╬šZ(y©│)┴xÖz╦„
ĪĪĪĪ·Ęų╬÷ę²ŪµŻ║▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų╬÷(╚ńąąŪķĘų╬÷ĪóųĖś╦(bi©Īo)▒O(ji©Īn)┐žĪół¾(b©żo)▒Ē)
ĪĪĪĪé„Įy(t©»ng)ū÷Ę©╩Ūīó▀@ą®╣”─▄▓Ęų│╔ČÓéĆ(g©©)¬Ü(d©▓)┴óĮM╝■Ż¼ĮM│╔╦∙ų^Ą─“ČÓę²Ūµ╝▄śŗ(g©░u)”Ż¼└²╚ńŻ║
ĪĪĪĪ·╩╣ė├ MongoDB ╗“ HBase ū÷Ęų▓╝╩Į┤µā”(ch©│);
ĪĪĪĪ·ė├ Elasticsearch ╠Ä└Ē╚½╬─Öz╦„;
ĪĪĪĪ·ė├Ž“┴┐öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ū÷ vector Öz╦„;
ĪĪĪĪ·ė├ ClickHouse ╗“ Snowflake ł╠(zh©¬)ąąĘų╬÷╚╬äš(w©┤)ĪŻ
ĪĪĪĪ▀@ĘN╝▄śŗ(g©░u)ļm╚╗╣”─▄²R╚½Ż¼Ą½┤µį┌╚²┤¾å¢(w©©n)Ņ}Ż║
ĪĪĪĪ·ŽĄĮy(t©»ng)▀\(y©┤n)ŠSÅ═(f©┤)ļsŻ║ąĶ╣▄└ĒČÓéĆ(g©©)╝╝ąg(sh©┤)ŚŻŻ¼░µ▒Šę└┘ćĪó▓┐╩Īó▀\(y©┤n)ŠSē║┴”┤¾;
ĪĪĪĪ·öĄ(sh©┤)ō■(j©┤)ĖŅ┴čć└(y©ón)ųžŻ║öĄ(sh©┤)ō■(j©┤)ąĶį┌ČÓéĆ(g©©)ŽĄĮy(t©»ng)ķgĘ┤Å═(f©┤)═¼▓ĮĪóÅ═(f©┤)ųŲŻ¼┐┌ÅĮļyĮy(t©»ng)ę╗;
ĪĪĪĪ·ąį─▄║═Ēææ¬(y©®ng)µ£┬ĘķL(zh©Żng)Ż║▓ķįāąĶ┐ńŽĄĮy(t©»ng)Ų┤ĮėŻ¼ė░ĒæĒææ¬(y©®ng)Ģr(sh©¬)ķg║═ĘĆ(w©¦n)Č©ąįĪŻ
ĪĪĪĪ╬ęéāīó▀@ĘN╝▄śŗ(g©░u)ĘQ×ķĄõą═Ą─ Legacy Data ArchitectureŻ©é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)╝▄śŗ(g©░u)Ż®ĪŻ╦³ęčĮø(j©®ng)ļyęį▀m┼õ AI Ģr(sh©¬)┤·╚šęµį÷ķL(zh©Żng)Ą─īŹ(sh©¬)Ģr(sh©¬)ąįĪóĮy(t©»ng)ę╗ąį║═ųŪ─▄╗»ąĶŪ¾ĪŻ

ĪĪĪĪData Warebase Ą──┐ś╦(bi©Īo)Ż¼š²╩Ū═©▀^(gu©░)Įy(t©»ng)ę╗╝▄śŗ(g©░u)Ż¼īóČÓ─ŻöĄ(sh©┤)ō■(j©┤)─▄┴”╝»│╔ė┌ę╗éĆ(g©©)ŲĮ┼_(t©ói)ų«╔ŽŻ¼ęįĖ³║å(ji©Żn)ØŹĄ─ĘĮ╩Įų¦│ųÅ═(f©┤)ļs AI WorkflowĪŻ╦³▓╗╩ŪīóČÓéĆ(g©©)ę²Ūµ║å(ji©Żn)å╬Ų┤čbŻ¼Č°╩ŪÅ─Ąūīė╝▄śŗ(g©░u)ķ_(k©Īi)╩╝╚┌║Ž╩┬äš(w©┤)╠Ä└ĒĪó╦č╦„ę²ŪµĪóŽ“┴┐Öz╦„║═īŹ(sh©¬)Ģr(sh©¬)Ęų╬÷Ż¼šµš²ū÷ĄĮ“ę╗éĆ(g©©)ŽĄĮy(t©»ng)Īó╚½ł÷(ch©Żng)Š░Ė▓╔w”ĪŻ
ĪĪĪĪData Warebase ▒Š┘|(zh©¼)╔Ž╩Ūę╗éĆ(g©©)ČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)
ĪĪĪĪš²╚ńų«Ū░ėæšōĄ─Ż¼Äū║§╦∙ėąĄ─öĄ(sh©┤)ō■(j©┤)å¢(w©©n)Ņ}└Ēæ¬(y©®ng)ė╔ę╗éĆ(g©©)Įy(t©»ng)ę╗Ą─öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)ĮŌøQŻ¼Č°▀@éĆ(g©©)ŽĄĮy(t©»ng)▒žĒÜī”(du©¼) AI ėč║├ĪŻAI Agent ąĶę¬ę╗éĆ(g©©)ČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)üĒ(l©ói)╠Ä└ĒČÓĘNöĄ(sh©┤)ō■(j©┤)ŅÉą═║═╚╬äš(w©┤)Ż¼▀@ę╗³c(di©Żn)╬ęéāų«Ū░ęčĮø(j©®ng)ųv▀^(gu©░)ĪŻ
ĪĪĪĪ«ö(d©Īng)┐═æ¶å¢(w©©n)ĄĮ╚ń║╬īŹ(sh©¬)¼F(xi©żn)▀@éĆ(g©©)─┐ś╦(bi©Īo)Ģr(sh©¬)Ż¼ūŅ│§╦¹éā═∙═∙ļyęįŽÓą┼ę╗éĆ(g©©)ŽĄĮy(t©»ng)─▄╝»│╔╚ń┤╦ČÓĄ─╣”─▄Ż¼ę“?y©żn)ķ╠¶æ?zh©żn)┤_īŹ(sh©¬)║▄┤¾ĪŻ║å(ji©Żn)å╬üĒ(l©ói)šf(shu©Ł)Ż¼╚ń╣¹öĄ(sh©┤)ō■(j©┤)┴┐ų╗ėą 100 ąąŻ¼īŹ(sh©¬)¼F(xi©żn)ų«Ū░╠ߥĮĄ─╣”─▄▓ó▓╗ļyŻ¼┤¾ČÓöĄ(sh©┤)å╬ÖC(j©®)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Č╝─▄▌p╦╔ä┘╚╬ĪŻĄ½«ö(d©Īng)öĄ(sh©┤)ō■(j©┤)┴┐▀_(d©ó)ĄĮ 1 ā|Īó10 ā|╔§ų┴ 100 ā|ąąĢr(sh©¬)Ż¼╠¶æ(zh©żn)▓┼šµš²ķ_(k©Īi)╩╝ĪŻ

ĪĪĪĪę“┤╦Ż¼Data Warebase Ą─║╦ą─Ėé(j©¼ng)ĀÄ(zh©źng)┴”į┌ė┌ų¦│ųąą┴ą╗ņ┤µŪęŠ▀ėąĘų▓╝╩ĮÖMŽ“╦«ŲĮöU(ku©░)š╣Ą──▄┴”ĪŻ▀@ĘN─▄┴”ų„ę¬ę└┘ć╚²éĆ(g©©)ĻP(gu©Īn)µI╝╝ąg(sh©┤)ų¦ō╬Ż║┤µā”(ch©│)Īó╦„ę²║═┤µ╦ŃĘųļxĪŻ
ĪĪĪĪ┤“įņ Data Warebase Ą─║╦ą─╚²ę¬╦žŻ║┤µā”(ch©│)Īó╦„ę²║═┤µ╦ŃĘųļx
ĪĪĪĪ1.┤µā”(ch©│)╝▄śŗ(g©░u)Ż║ņ`╗ŅČÓśėŻ¼╝µŅÖ OLTP/ ╦č╦„ /OLAP Ą─ąĶŪ¾
ĪĪĪĪ¤o(w©▓)šō╩Ūé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▀Ć╩Ū┤¾öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)Ż¼Č╝═©▀^(gu©░)ąą┤µā”(ch©│)ų¦│ų³c(di©Żn)▓ķ╗“Ė▀╦┘▓ķįāŻ¼═©▀^(gu©░)┴ą┤µā”(ch©│)ų¦│ųĘų╬÷║═╦č╦„ĪŻData Warebase ŽĄĮy(t©»ng)ųą╚╬║╬ę╗Åł▒Ēų¦│ų╚²ĘN┤µā”(ch©│)─Ż╩ĮŻ║ąą┤µ▒ĒĪó┴ą┤µ▒Ē║═ąą┴ą╗ņ┤µ▒ĒĪŻ
ĪĪĪĪ·ąą┤µŻ║▀mė├ė┌µIųĄ▓ķįā(KV)ł÷(ch©Żng)Š░Ż¼ų¦│ų┐ņ╦┘å╬ąąįLå¢(w©©n)ĪŻ
ĪĪĪĪ·┴ą┤µŻ║▀m║ŽĘų╬÷║═Ą╣┼┼╦„ę²Ż¼ų¦│ųĖ▀ą¦ē║┐s║═┴ą╝ē(j©¬)Æ▀├ĶĪŻ
ĪĪĪĪ·ąą┴ą╗ņ┤µŻ║į┌▓╗┤_Č©žō(f©┤)▌d╠žąįĢr(sh©¬)Ż¼ūįäė(d©░ng)╝µŅÖąą┤µ┼c┴ą┤µĄ─ā×(y©Łu)ä▌(sh©¼)ĪŻ

ĪĪĪĪ2.╦„ę²¾wŽĄŻ║╚½├µ / ═Ļš¹ / š²Į╗
ĪĪĪĪData Warebase īŹ(sh©¬)¼F(xi©żn)┴╦ČÓĘN╦„ę²ÖC(j©®)ųŲŻ¼░³└©Ż║
ĪĪĪĪ·OLTP Ą─╚½ŠųČ■╝ē(j©¬)╦„ę²Ż║ų¦│ų┐ń╣Ø(ji©”)³c(di©Żn)Ą─öĄ(sh©┤)ō■(j©┤)Č©╬╗ĪŻ
ĪĪĪĪ·Ą╣┼┼╦„ę²Ż║ØMūŃ╬─▒Š╦č╦„ąĶŪ¾ĪŻ
ĪĪĪĪ·┴ą┤µ╦„ę²Ż║ā×(y©Łu)╗»Ęų╬÷▓ķįāĪŻ
ĪĪĪĪ·JSON ╦„ę²Ż║ų¦│ų░ļĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─Ė▀ą¦įLå¢(w©©n)ĪŻ
ĪĪĪĪėą┴╦▀@ą®╦„ę²Ż¼ĮY(ji©”)║ŽųŪ─▄▓ķįāā×(y©Łu)╗»Ų„Ż¼ŽĄĮy(t©»ng)─▄ē“äė(d©░ng)æB(t©żi)▀xō±ūŅā×(y©Łu)ł╠(zh©¬)ąą┬ĘÅĮŻ¼īŹ(sh©¬)¼F(xi©żn)Å═(f©┤)ļs▓ķįāĄ─Ą═čė▀tĒææ¬(y©®ng)ĪŻÅ─└Ēšō╔ŽųvŻ¼▀@ą®╝╝ąg(sh©┤)į┌ęįŪ░Ė„ĘNöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)║═┤¾öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)Č╝ĘųäeīŹ(sh©¬)¼F(xi©żn)┴╦Ż¼╬ęéāų╗╩Ū░č▀@ą®╦„ę²─▄┴”Ę┼į┌┴╦ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ųą▓ó░č╦³┬õĄž│╔×ķ┴╦¼F(xi©żn)īŹ(sh©¬)ĪŻ

ĪĪĪĪ3.┤µ╦ŃĘųļxŻ║öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─įŲįŁ╔·äō(chu©żng)ą┬
ĪĪĪĪData Warebase ▓╔ė├įŲįŁ╔·╝▄śŗ(g©░u)įO(sh©©)ėŗ(j©¼)Ż¼īó┤µā”(ch©│)┼cėŗ(j©¼)╦Ń┘Yį┤ĮŌ±ŅŻ║
ĪĪĪĪ·ėŗ(j©¼)╦ŃīėŻ║ņ`╗ŅÅŚąįŻ¼ų¦│ų░┤ąĶöU(ku©░)š╣ĪŻ
ĪĪĪĪ·¤ß┤µā”(ch©│)īėŻ║▒ŻūCīŹ(sh©¬)Ģr(sh©¬)║═Į³īŹ(sh©¬)Ģr(sh©¬)öĄ(sh©┤)ō■(j©┤)įLå¢(w©©n)Ą─Ą═čė▀tĪŻ
ĪĪĪĪ·└õ┤µā”(ch©│)īėŻ║Įø(j©®ng)Ø·(j©¼)Ė▀ą¦Ż¼ØMūŃ║Ż┴┐Üv╩ĘöĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)Ż¼▓óŪęų¦│ųų▒Įė▓ķįā└õ┤µ╔ŽĄ─öĄ(sh©┤)ō■(j©┤)(═©▀^(gu©░)ę╗ą®╝▄śŗ(g©░u)Ą─ā×(y©Łu)╗»Ż¼└õ┤µ╔ŽĄ─▓ķįāčė▀t┐╔ęįū÷ĄĮĮėĮ³¤ß┤µŻ¼Ą½╩Ū═╠═┬Ģ■(hu©¼)▀h(yu©Żn)Ą═ė┌¤ß┤µ)ĪŻ

ĪĪĪĪ▓╗═¼ė┌é„Įy(t©»ng)┤¾öĄ(sh©┤)ō■(j©┤)┤µ╦ŃĘųļxų▒Įė╩╣ė├įŲ╔ŽĖ▀┐╔ė├Ą─ī”(du©¼)Ž¾┤µā”(ch©│)Ż¼Data Warebase į┌ēK┤µā”(ch©│)įŲ▒P(p©ón)╔Žūįų„įO(sh©©)ėŗ(j©¼)┴╦Ė▀ąį─▄Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼īŹ(sh©¬)¼F(xi©żn)┴╦į┌ŠĆöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝ē(j©¬)äeĄ─┤µ╦ŃĘųļxŻ¼▀@éĆ(g©©)╠¶æ(zh©żn)ę¬▒╚┤¾öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)Ą─┤µ╦ŃĘųļxļyę╗éĆ(g©©)öĄ(sh©┤)┴┐╝ē(j©¬)ĪŻ

ĪĪĪĪ═¼Ģr(sh©¬)Ż¼┤µ╦ŃĘųļx╝▄śŗ(g©░u)ĦüĒ(l©ói)Ą─├ļ╝ē(j©¬)ÅŚąį(infinite scale & scale to zero)Ż¼žō(f©┤)▌dĖ¶ļxŻ¼║═öĄ(sh©┤)ō■(j©┤)┐╦┬Ī(Branching)Ą──▄┴”Ż¼╩ŪīŹ(sh©¬)¼F(xi©żn) AI Agent ņ`╗Ņ╣żū„┴„║═ČÓł÷(ch©Żng)Š░▓ó░l(f©Ī)ėŗ(j©¼)╦ŃĄ─ĻP(gu©Īn)µIĪŻ

ĪĪĪĪ4.Ųõ╦¹ĻP(gu©Īn)µI─▄┴”

ĪĪĪĪ·öĄ(sh©┤)ō■(j©┤)Ęųģ^(q©▒)Ż©PartitioningŻ®Ż║╝Ü(x©¼)┴ŻČ╚öĄ(sh©┤)ō■(j©┤)äØĘųŻ¼ĘĮ▒Ń╣▄└ĒöĄ(sh©┤)ō■(j©┤)Ż¼į┌─│ą®ł÷(ch©Żng)Š░Ž┬┐╔╠ß╔²▓ķįāąį─▄ĪŻ
ĪĪĪĪ·īŹ(sh©¬)Ģr(sh©¬)į÷┴┐╬’╗»ęĢłDŻ║═╗ŲŲé„Įy(t©»ng)╬’╗»ęĢłD“╚½┴┐ųžėŗ(j©¼)╦Ń”Ą─Ų┐ŅiŻ¼īŹ(sh©¬)¼F(xi©żn) Subsecond ╝ē(j©¬)äeĄ─į÷┴┐Ė³ą┬Ż¼śO┤¾║å(ji©Żn)╗»īŹ(sh©¬)Ģr(sh©¬) Transform ┴„│╠ĪŻ
ĪĪĪĪ·Ģr(sh©¬)ķg┬├ąąŻ©Time TravelŻ®╣”─▄Ż║ų¦│ų╗∙ė┌Ģr(sh©¬)ķgŠSČ╚Ą─öĄ(sh©┤)ō■(j©┤)░µ▒Š╣▄└ĒŻ¼ØMūŃ AI ė¢(x©┤n)ŠÜ▀^(gu©░)│╠ųąĄ─╠žš„ūĘ█Ö┼cÜv╩ĘöĄ(sh©┤)ō■(j©┤)╗ž╦▌ąĶŪ¾ĪŻ
ĪĪĪĪ┐éĮY(ji©”)ę╗Ž┬Ż¼Data Warebase Ą─šQ╔·ų«│§Š═ŅA(y©┤)ęŖ(ji©żn)ĄĮ╬┤üĒ(l©ói)Ą─╦∙ėąæ¬(y©®ng)ė├ŽĄĮy(t©»ng)īó build į┌ā╔éĆ(g©©) API ų«╔ŽŻ║ę╗éĆ(g©©)╩Ū Data APIŻ¼┴Ēę╗éĆ(g©©)╩Ū AI APIĪŻ ╬ęéāīŻūóė┌ū÷║├ Data APIŻ¼Č°╦³ŪĪ║├į┌ AI ŅI(l©½ng)ė“ę▓─▄ØMūŃ AI Workflow Ą─╦∙ėąąĶŪ¾ĪŻ╬ęéāŽ┬├µüĒ(l©ói)┐┤┐┤╦³╩Ū╚ń║╬ØMūŃ▀@ą®ąĶŪ¾Ą─ĪŻ

ĪĪĪĪData Warebase for AI WorkloadŻ║╚ń║╬ų¦ō╬ AI ╣żū„žō(f©┤)▌d
ĪĪĪĪ×ķ┴╦ØMūŃ AI workload ąĶŪ¾Ż¼Data Warebase ąĶę¬═Ļ│╔öĄ(sh©┤)ō■(j©┤)Įė╚ļŻ©IngestionŻ®Īó▐D(zhu©Żn)ōQŻ©TransformŻ®Īó╠Į╦„Ż©ExploreŻ®║═Öz╦„Ż©RetrieveŻ®ĪŻ╬ęéāĘųäeüĒ(l©ói)┐┤▀@ÄūéĆ(g©©)Łh(hu©ón)╣Ø(ji©”)Ż║

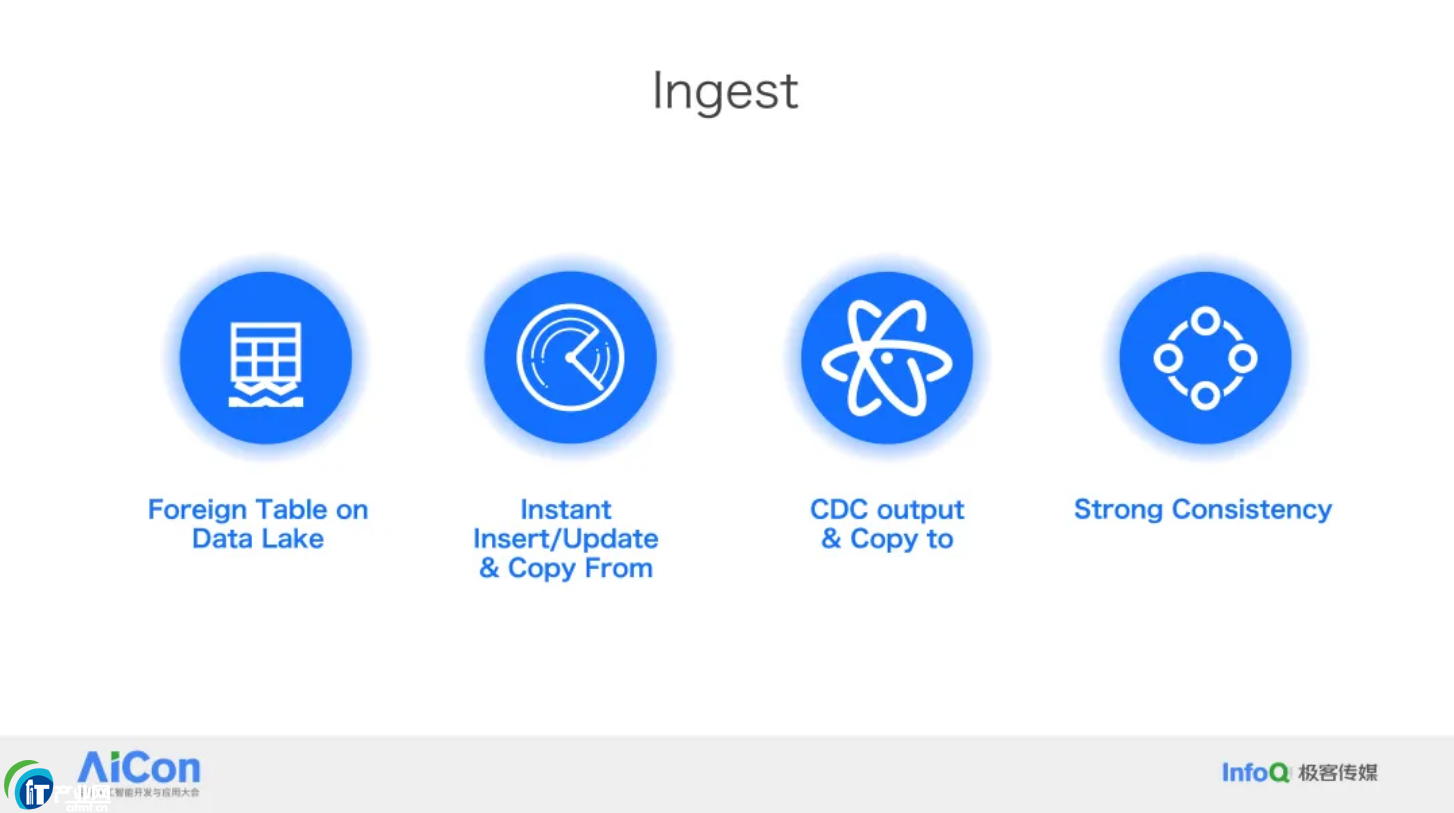
ĪĪĪĪ1.Ingestion
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)▀M(j©¼n)üĒ(l©ói)Ģr(sh©¬)Ż¼╩ūŽ╚ąĶę¬─▄ē“┐ņ╦┘Ąžī¦(d©Żo)╚ļĪŻData Warebase ─▄ē“ų¦│ų?j©½n)?sh©┤)ō■(j©┤)Äņ(k©┤)╝ē(j©¬)äeĄ─╝┤Ģr(sh©¬)į÷ähĖ─▓ķ▓┘ū„Ż¼▒ŻšŽ┴╦öĄ(sh©┤)ō■(j©┤)“īæ(xi©¦)╚ļ╝┤┐╔ęŖ(ji©żn)”Ż¼═¼Ģr(sh©¬)╦³ų¦│ų═©▀^(gu©░) Foreign Table ų▒ĮėÅ─ Data Lake ųąūx╚ĪöĄ(sh©┤)ō■(j©┤)ĪŻ┤╦═ŌŻ¼ū„×ķę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼╦³▀Ćų¦│ų CDC ▌ö│÷Ż¼Č°įSČÓ┤¾öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)▓ó▓╗ų¦│ų▀@ę╗³c(di©Żn)ĪŻ▀@ĘN─▄┴”┤_▒Ż┴╦š¹éĆ(g©©) Workflow ┐╔ęį¤o(w©▓)┐p┤«┬ō(li©ón)ŲüĒ(l©ói)Ż¼═¼Ģr(sh©¬)▒ŻūC┴╦öĄ(sh©┤)ō■(j©┤)┤µā”(ch©│)Ą─ÅŖ(qi©óng)ę╗ų┬ąįĪŻ
ĪĪĪĪ2.Transform
ĪĪĪĪį┌ Transform Łh(hu©ón)╣Ø(ji©”)Ż¼╬ęšJ(r©©n)×ķūŅųžę¬Ą─╣”─▄ėą╚²éĆ(g©©)Ż║
ĪĪĪĪ·īŹ(sh©¬)Ģr(sh©¬)į÷┴┐╬’╗»ęĢłD
ĪĪĪĪ·Schema Evolving
ĪĪĪĪ·Generated Columns ║═ Built-in FunctionsĪŻ
ĪĪĪĪ╩ūŽ╚Ż¼īŹ(sh©¬)Ģr(sh©¬)į÷┴┐╬’╗»ęĢłD┐╔ęįĖ▀ą¦Ąž╠Ä└ĒöĄ(sh©┤)ō■(j©┤)Ą─īŹ(sh©¬)Ģr(sh©¬)Ė³ą┬║═▓ķįāŻ¼┤¾┤¾╠ß╔²┴╦öĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─ą¦┬╩ĪŻ┤¾▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)Äņ(k©┤)ŽĄĮy(t©»ng)ų╗ų¦│ų╚½┴┐╬’╗»ęĢłD║═ĘŪ│ŻėąŽ▐Ą─į÷┴┐╬’╗»ęĢłD─▄┴”Ż¼╦∙ęįė├æ¶═∙═∙▀ĆąĶę¬ Flink ▀@ĘN«a(ch©Żn)ŲĘū÷öĄ(sh©┤)ō■(j©┤)Ą─ TransformĪŻData Warebase īŹ(sh©¬)¼F(xi©żn)┴╦═Ļš¹┴╦į÷┴┐╬’╗»ęĢłDĄ──▄┴”Ż¼ęį║¾öĄ(sh©┤)ō■(j©┤)Ą─ Instant Transform į┘ę▓▓╗ąĶę¬ Flink ┴╦ĪŻŲõ┤╬Ż¼Schema Evolving į╩įSöĄ(sh©┤)ō■(j©┤)─Ż╩Įņ`╗Ņč▌ūāŻ¼─▄ē“▀mæ¬(y©®ng)▓╗öÓūā╗»Ą─öĄ(sh©┤)ō■(j©┤)ĮY(ji©”)śŗ(g©░u)ĪŻį┘┤╬Ż¼Generated Columns ╣”─▄ę▓ĘŪ│ŻÅŖ(qi©óng)┤¾ĪŻė├æ¶┐╔ęįų▒Įėį┌įŁ▒Ē╔Ž╠Ē╝ėę╗éĆ(g©©)ą┬Ą─ėŗ(j©¼)╦Ń┴ąŻ¼Č°¤o(w©▓)ąĶ╩╣ė├╬’╗»ęĢłDŻ¼▀@╩╣Ą├ Transform ūāĄ├ĘŪ│Ż╚▌ęūŻ¼│╔▒ŠĖ³Ą═ĪŻūŅ║¾Ż¼Built-in Functions ┐╔ęį▌p╦╔ĮŌøQ┤¾┴┐öĄ(sh©┤)ō■(j©┤)╝ė╣żĄ─ ETL ╣żū„ĪŻ

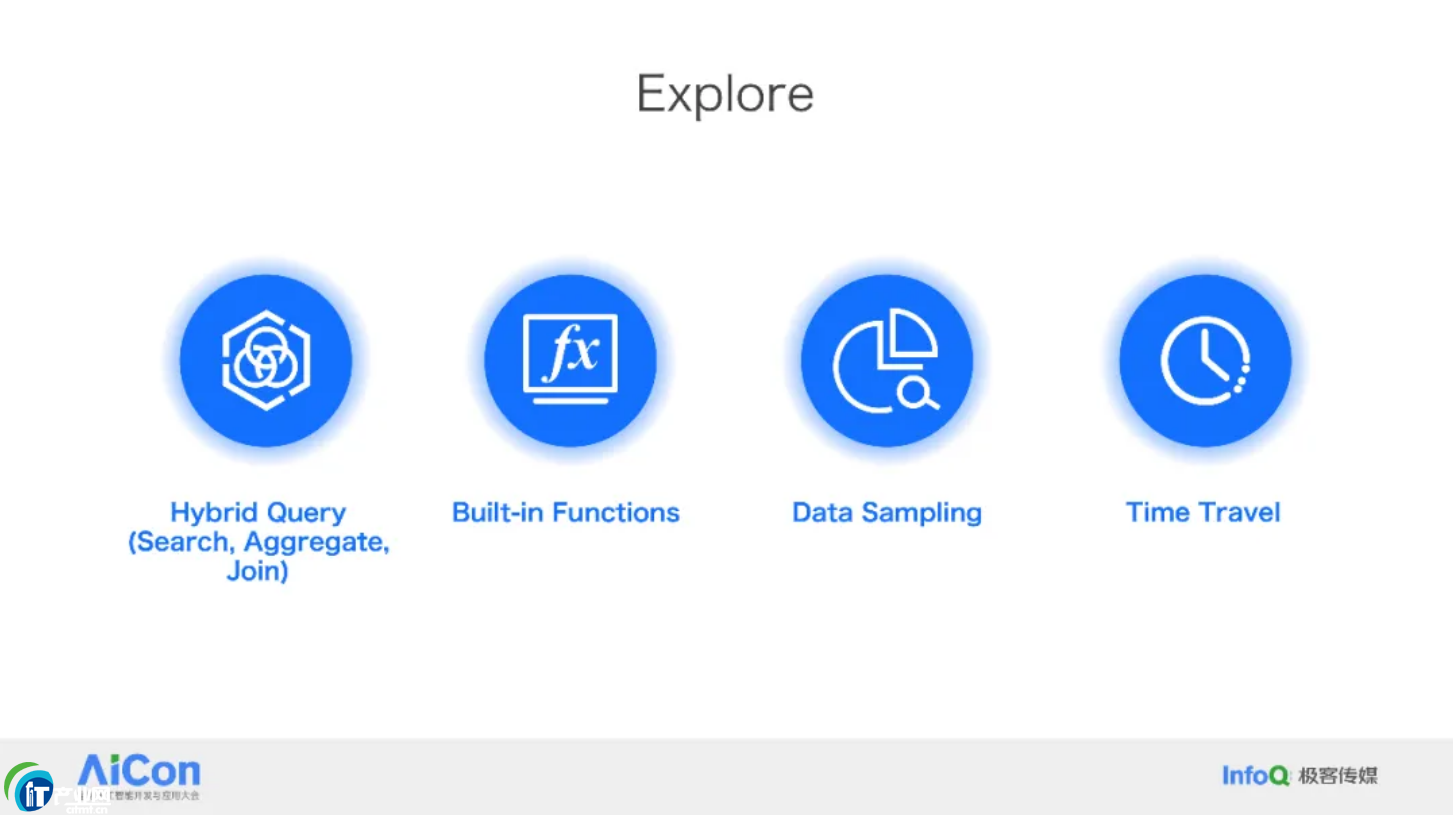
ĪĪĪĪ3. Explore
ĪĪĪĪį┌öĄ(sh©┤)ō■(j©┤)Įø(j©®ng)▀^(gu©░) Transform ų«║¾Ż¼ė├æ¶ąĶę¬į┌╔Ž├µ▀M(j©¼n)ąąĖ„╩ĮĖ„śėĄ─▓ķįā║═Ęų╬÷ĪŻ╬ęäé▓┼╠ߥĮŻ¼ČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĘŪ│Żųžę¬Ż¼ę“?y©żn)ķ║▄ČÓ▓ķįā▓╗āHāH╩Ū╝āĘų╬÷ą═ OLAP Ą─Ż¼ę▓▓╗╩Ū╝ā╩┬äš(w©┤)ą═Ą─Ż¼Č°╩ŪąĶę¬╗ņ║Žą═Ą─▓ķįā─▄┴”ĪŻ┤╦═ŌŻ¼ī”(du©¼)ė┌ AI ╣ż│╠ĤüĒ(l©ói)šf(shu©Ł)Ż¼Sampling ╣”─▄ę▓ĘŪ│Żųžę¬Ż¼ę“?y©żn)ķ╦¹éāąĶę¬═©▀^(gu©░)▓╔śėüĒ(l©ói)ė^▓ņöĄ(sh©┤)ō■(j©┤)Ą─┌ģä▌(sh©¼)ĪŻūŅ║¾Ż¼š²╚ńäé▓┼╠ߥĮĄ─Ż¼į┌ėąą®Ģr(sh©¬)║“╦ŃĘ©╣ż│╠ĤąĶę¬čąŠ┐ Feature Ą─ūā╗»ī”(du©¼)─Żą═Ą─ė░ĒæŻ¼ę“┤╦╦¹éāąĶę¬ų¬Ą└ę╗éĆ(g©©) Feature į┌▓╗═¼Ģr(sh©¬)ķg³c(di©Żn)Ą─Š½┤_öĄ(sh©┤)ųĄŻ¼į┌Ųš═©Ą─┤¾öĄ(sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)ųąŻ¼▀@ąĶę¬▓╗öÓĄž┤µā”(ch©│)╦∙ėą Feature ▓╗═¼Ģr(sh©¬)ķgĄ─öĄ(sh©┤)ųĄŻ¼įņ│╔┤¾┴┐Ą─┤µā”(ch©│)└╦┘M(f©©i)ĪŻData Warebase ū„×ķę╗┐ŅöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ų¦│ų Transaction ║═ MVCCŻ¼ę“┤╦ėą║▄║├Ą─ built-in Ą─ Time Travel Ą──▄┴”Ż¼┐╔ęįĮo╦ŃĘ©═¼īW(xu©”)╠ß╣®Ą═│╔▒ŠĄ─ Feature ░┤Ģr(sh©¬)ą“ė^£y(c©©)Ą──▄┴”ĪŻ
ĪĪĪĪ4.Retrieve
ĪĪĪĪį┌ Retrieve Łh(hu©ón)╣Ø(ji©”)Ż¼ūŅĻP(gu©Īn)µIĄ─╩Ūę¬─▄ū÷ČÓ─ŻÖz╦„ĪŻ╚ń╣¹ø](m©”i)ėąČÓ─ŻÖz╦„Ą──▄┴”Ż¼║▄ČÓæ¬(y©®ng)ė├ł÷(ch©Żng)Š░Äū║§╩Ū¤o(w©▓)Ę©īŹ(sh©¬)¼F(xi©żn)Ą─ĪŻäé▓┼ĮķĮBĄ─ÄūéĆ(g©©)Š▀¾wł÷(ch©Żng)Š░Ż¼ę▓┐┤ĄĮ┴╦įĮüĒ(l©ói)įĮČÓĄ─ł÷(ch©Żng)Š░ąĶę¬▀@ĘN─▄┴”ĪŻę“┤╦Ż¼ČÓ─ŻÖz╦„─▄┴”øQČ©┴╦ŽĄĮy(t©»ng)į┌╠Ä└ĒĖ³Å═(f©┤)ļsł÷(ch©Żng)Š░Ģr(sh©¬)Ą─▒Ē¼F(xi©żn)Ż¼ė╚Ųõ╩Ū«ö(d©Īng)öĄ(sh©┤)ō■(j©┤)┴┐į÷┤¾Ģr(sh©¬)ĪŻ╚ń╣¹öĄ(sh©┤)ō■(j©┤)┴┐║▄ąĪŻ¼▒╚╚ńų╗ėą 100 ąąöĄ(sh©┤)ō■(j©┤)Ż¼─Ū├┤å¢(w©©n)Ņ}▓╗┤¾Ż¼Ą½ļSų°öĄ(sh©┤)ō■(j©┤)┴┐Ą─į÷╝ėŻ¼▀@ĘN─▄┴”Š═’@Ą├ė╚×ķųžę¬ĪŻ

ĪĪĪĪUse Cases of Data WarebaseŻ║Ąõą═┬õĄžł÷(ch©Żng)Š░
ĪĪĪĪĮėŽ┬üĒ(l©ói)ĘųŽĒÄūéĆ(g©©) Data Warebase ┬õĄž░Ė└²ĪŻ║å(ji©Żn)å╬üĒ(l©ói)šf(shu©Ł)Ż¼┐╔Ęų×ķ┴∙┤¾ŅÉĪŻĄ½Å─│ķŽ¾īė├µüĒ(l©ói)ųvŻ¼ŲõīŹ(sh©¬)ų╗ėąā╔┤¾ŅÉą═ĪŻ
ĪĪĪĪ·ę└┐┐ČÓ─Ż─▄┴”Š½║å(ji©Żn)╝▄śŗ(g©░u)(Simplicity)Ż║└²╚ń AI Agent ║═ Feature StoreŻ¼ ╬┤üĒ(l©ói)┤¾▓┐ĘųĘ■äš(w©┤)īóę└═ą AI Agent ▀M(j©¼n)ąąųŪ─▄Į╗╗źŻ¼Č° AI Agent ąĶę¬ę╗éĆ(g©©)ÅŖ(qi©óng)┤¾Ą─ Data APIŻ¼Data Warebase ╠ß╣®┴╦ÅŖ(qi©óng)┤¾Ą─ČÓ─Ż▓ķįāĪóśOų┬ÅŚąįĪóęį╝░Ęųų¦╣▄└ĒĄ──▄┴”Ż¼─▄ē“║▄║├Ąžų¦│ų AI Agent Ą─ł÷(ch©Żng)Š░ĪŻ
ĪĪĪĪ·īŹ(sh©¬)Ģr(sh©¬)øQ▓▀ (Instant Decision)Ż║ └²╚ń│¼īŹ(sh©¬)Ģr(sh©¬)Ė▀═╠═┬Ą─Į╚┌ąąŪķĘų╬÷║═’L(f©źng)┐žŻ¼Ė▀ÅŚąįĖ▀═╠═┬Ą─▀\(y©┤n)ŠS┐╔ė^£y(c©©)ąįł÷(ch©Żng)Š░Ż¼▄ć(ch©ź)┬ō(li©ón)ŠW(w©Żng)▄ć(ch©ź)ÖC(j©®)ą┼╠¢(h©żo)īŹ(sh©¬)Ģr(sh©¬)▒O(ji©Īn)┐ž┼c╣╩šŽį\öÓąĶŪ¾Ż¼ęį╝░īŹ(sh©¬)Ģr(sh©¬)╦č╦„ÅVĖµ═Ų╦]ŽĄĮy(t©»ng)ĪŻ

ĪĪĪĪĻP(gu©Īn)ė┌ AI AgentŻ¼ų«Ū░ęčĮø(j©®ng)ĮŌßī▀^(gu©░)▓╗į┘┘ś╩÷ĪŻInstant Decision Ž┬Ą─ę╗éĆ(g©©)┤¾ŅÉ╩Ū┐╔ė^£y(c©©)ąįĪŻ┐╔ė^£y(c©©)ąįÅ─ÅV┴x╔ŽüĒ(l©ói)šf(shu©Ł)Ż¼╚f(w©żn)╬’╦Ų║§Č╝Š▀éõ┐╔ė^£y(c©©)ąįŻ¼Ą½▀@éĆ(g©©)ĘČ«Ā╠½īÆĘ║┴╦ĪŻČ°¬M┴xĄ─┐╔ė^£y(c©©)ąįŻ¼ų„ę¬╩ŪųĖī”(du©¼)╚šųŠĪóś╦(bi©Īo)║×║═ąą×ķĄ─Ęų╬÷ĪŻęįŪ░Ż¼▀@éĆ(g©©)ŅI(l©½ng)ė“ų„ę¬╩ŪĢr(sh©¬)ą“öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─╠ņŽ┬ĪŻ╚╗Č°Ż¼┤¾╝ę║¾üĒ(l©ói)░l(f©Ī)¼F(xi©żn)Ģr(sh©¬)ą“öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)┤µį┌ę╗ą®ŠųŽ▐ąįŻ¼▒╚╚ń╦³ų╗─▄ū÷öĄ(sh©┤)ō■(j©┤)Ą─ Append ▓Õ╚ļŻ¼▓╗─▄ UpdateŻ¼ę▓¤o(w©▓)Ę©▀M(j©¼n)ąą╬─▒ŠÖz╦„║═Å═(f©┤)ļsĄ─Ęų╬÷▓ķįāĪŻ
ĪĪĪĪė┌╩ŪŻ¼┤¾╝ęķ_(k©Īi)╩╝╩╣ė├ ES ║═ ClickHouseĪŻ▓╗▀^(gu©░)Ż¼ES ūŅ┤¾Ą─å¢(w©©n)Ņ}╩Ū└õ¤ßöĄ(sh©┤)ō■(j©┤)ĘųīėĄ─╠¶æ(zh©żn)(└õöĄ(sh©┤)ō■(j©┤)ąĶę¬ųžą┬╝ė▌dŻ¼Ę±ät¤o(w©▓)Ę©ų▒ĮėįLå¢(w©©n))Ż¼Č°Ūę╦³ų„ę¬ų╗─▄ė├ė┌ś╦(bi©Īo)║×▀^(gu©░)×V║═╬─▒ŠÖz╦„ĪŻClickHouse į┌┤¾īÆ▒Ē╔Žū÷ČÓŠSĘų╬÷Ą─ąį─▄ĘŪ│Ż▓╗Õe(cu©░)Ż¼Ą½╦³Ą─ Upsert ─▄┴”║═ Join ▓┘ū„ąį─▄▓ó▓╗└ĒŽļĪŻĖ³ųžę¬Ą─╩ŪŻ¼į┌┐╔ė^£y(c©©)ąįł÷(ch©Żng)Š░Ž┬Ż¼ÅŚąį─▄┴”ų┴ĻP(gu©Īn)ųžę¬ĪŻę“?y©żn)ķį┌ŽĄĮy(t©»ng)š²│Ż▀\(y©┤n)ąąĪóø](m©”i)ėął¾(b©żo)Š»╗“ąąŪķŲĮĘĆ(w©¦n)Ģr(sh©¬)Ż¼┐╔─▄ų╗ėąąĪÄūéĆ(g©©)╚╦į┌ė^£y(c©©);Č°ę╗Ą®ŽĄĮy(t©»ng)│÷¼F(xi©żn)å¢(w©©n)Ņ}╗“š▀üĒ(l©ói)┴╦ę╗▓©ą┬Ą─Į╚┌ąąŪķŻ¼Ģ■(hu©¼)ėąĖ³ČÓĄ─╚╦ė┐╚ļ▓ķ┐┤Ż¼ŽĄĮy(t©»ng)║▄╚▌ęū▒└ØóĪŻę“┤╦Ż¼įŲ╔ŽĄ─ÅŚąį─▄┴”ĘŪ│Żųžę¬ĪŻData Warebase ę“?y©żn)ķ╩╣ė├┴╦ūŅŅI(l©½ng)Ž╚Ą─┤µ╦ŃĘųļx╝▄śŗ(g©░u)Ż¼┐╔ęįū÷ĄĮśI(y©©)äš(w©┤)¤o(w©▓)ĖąŪķørŽ┬Ą─├ļ╝ē(j©¬)ÅŚąįöU(ku©░)┐s╚▌ĪŻ
ĪĪĪĪ╦∙ęįŻ¼ŲõīŹ(sh©¬)┐╔ė^£y(c©©)ąįł÷(ch©Żng)Š░╝┤ąĶę¬ Simplicity ėųąĶę¬ Instant Decision Ą──▄┴”ĪŻ
ĪĪĪĪČ°į┌Į╚┌ŅI(l©½ng)ė“Ż¼Ž± TradingĪóFraud DetectionŻ¼ęį╝░▄ć(ch©ź)┬ō(li©ón)ŠW(w©Żng)ŅI(l©½ng)ė“ųąĄ─ą┼╠¢(h©żo)╩š╝»ĪóÖz£y(c©©)║═ł¾(b©żo)Š»Ż¼ęį╝░ AdsĪóSearch ║═ Recommendation ▀@ÄūŅÉł÷(ch©Żng)Š░ųąŻ¼╦³éāČ╝ī┘ė┌ąĶę¬ Instant Decision Ą─ł÷(ch©Żng)Š░ĪŻĮėŽ┬üĒ(l©ói)ĮķĮBÄūéĆ(g©©)Š▀¾w░Ė└²ĪŻ
ĪĪĪĪ░Ė└²ę╗Ż║AI Agent
ĪĪĪĪ╬┤üĒ(l©ói)Ą─ AI AgentŻ¼▓╗ąĶę¬ī”(du©¼)ĮėČÓéĆ(g©©) MCPŻ¼Č°╩Ū▀BĮėę╗éĆ(g©©)ČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪŻė├ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ę╗éĆ(g©©) MCP Įė┐┌Ż¼śO┤¾ĮĄĄ═ LLM ┤¾─Żą═Ą─ųŪ┴”║══Ų└ĒĄ─ķT(m©”n)ÖæĪŻ

ĪĪĪĪ╩ūŽ╚╩Ū AI AgentĪŻ╬┤üĒ(l©ói)Ż¼╦∙ėąĄ─Ę■äš(w©┤)Č╝īó╠ß╣® AI Agent Ą─Ę■äš(w©┤)ĪŻęį╬ęéāĄ─«a(ch©Żn)ŲĘ×ķ└²Ż¼Ģ■(hu©¼)│÷¼F(xi©żn)ų┴╔┘ā╔éĆ(g©©)┤¾Ą─ MCP │÷┐┌ĪŻ
ĪĪĪĪĄ┌ę╗éĆ(g©©) MCP ╩ŪöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▒Š╔ĒĪŻ ╬ęéāė├ś╦(bi©Īo)£╩(zh©│n)Ą─ PG MCP Š═┐╔ęį░čöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ę■äš(w©┤)▒®┬ČĮo┤¾─Żą═š{(di©żo)ė├ĪŻ┐═æ¶╝╚┐╔ęį╩╣ė├ SQL üĒ(l©ói)▓ķįāŻ¼ę▓┐╔ęį═©▀^(gu©░)┤¾─Żą═üĒ(l©ói)įLå¢(w©©n)╬ęéāĄ─«a(ch©Żn)ŲĘŻ¼╩╣ė├ Data Warebase Ģ■(hu©¼)ūāĄ├Ė³╝ė║å(ji©Żn)å╬ĪŻ
ĪĪĪĪĄ┌Č■éĆ(g©©) MCP ╩ŪŲĮ┼_(t©ói)Ę■äš(w©┤)ĪŻ │²┴╦öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▒Š╔ĒŻ¼Data Warebase ▀Ć╠ß╣®ŲĮ┼_(t©ói)Ę■äš(w©┤)(öU(ku©░)┐s╚▌Ż¼▒O(ji©Īn)┐žŻ¼ł¾(b©żo)Š»)Ż¼▀@ą®ŲĮ┼_(t©ói)Ę■äš(w©┤)ę▓┐╔ęįī”(du©¼)═Ō▒®┬Č MCP Ę■äš(w©┤)ĪŻ▀@śėŻ¼┐═æ¶Ą─ OPS ŽĄĮy(t©»ng)┐╔ęį═©▀^(gu©░) AI üĒ(l©ói)ųŪ─▄┴╦ĮŌöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─▀\(y©┤n)ąąŪķørĪŻ▀\(y©┤n)ŠS═¼īW(xu©”)┐╔ęįų▒Įė╠ß│÷Š▀¾wĄ─å¢(w©©n)Ņ}Ż¼▒╚╚ń“Į±╠ņę╗╠ņųą──éĆ(g©©)Ģr(sh©¬)ķg³c(di©Żn)Ą─ Workload ūŅĖ▀?”“Į±╠ņĄ─ Workload ▒╚ū“╠ņĖ▀┴╦ČÓ╔┘?”“ėą──ą®ųĖś╦(bi©Īo)ėąą®«É│Ż?”.
ĪĪĪĪŲĮ┼_(t©ói)Ę■äš(w©┤)ęįŪ░ų„ę¬╩Ū═©▀^(gu©░) SDK üĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)Ą─Ż¼Ą½¼F(xi©żn)į┌Č╝▐D(zhu©Żn)Ž“┴╦ MCPĪŻ╬┤üĒ(l©ói)æ¬(y©®ng)ė├īėĄ─śI(y©©)äš(w©┤)▀ē▌ŗĢ■(hu©¼)įĮüĒ(l©ói)įĮ▒ĪŻ¼śI(y©©)äš(w©┤)æ¬(y©®ng)ė├┬²┬²Ą─Č╝Ģ■(hu©¼)ūā│╔ų╗ė╔Ū░Č╦Įń├µĪóAI ║═öĄ(sh©┤)ō■(j©┤)▀@ 3 īė╝▄śŗ(g©░u)üĒ(l©ói)ų¦│ųĪŻ
ĪĪĪĪ┴Ē═ŌŻ¼╬ęäé▓┼╠ߥĮĄ─ Data Warebase Ą─╗ņ║Ž▓ķįā─▄┴”ĘŪ│ŻÅŖ(qi©óng)ĪŻė├æ¶į┘ę▓▓╗ė├ō·(d©Īn)ą─ę¬╣▄└ĒČÓéĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Š═─▄ĖŃČ©┤¾▓┐ĘųĄ─╩┬ŪķĪŻ┤╦═Ō Data Warebase ▀Ćų¦│ų Scale to ZeroŻ¼ę▓Š═╩Ūšf(shu©Ł)Ż¼«ö(d©Īng)ø](m©”i)ėą▀BĮė║═ Activity Ą─Ģr(sh©¬)║“Ż¼ėŗ(j©¼)╦Ń┘Yį┤┐╔ęįų▒ĮėßīĘ┼Ą¶ĪŻ═¼Ģr(sh©¬)Ż¼╦³ę▓─▄ų¦│ų¤o(w©▓)Ž▐Ą─╦«ŲĮöU(ku©░)╚▌ĪŻūŅ║¾Ż¼äé▓┼╠ߥĮĄ─┤µ╦ŃĘųļx╝▄śŗ(g©░u)─▄ē“║▄║├Ąžų¦│ų?j©½n)?sh©┤)ō■(j©┤) Snapshot Ą─┐ņ╦┘?g©░u)?f©┤)ųŲŻ¼┐╔ęį║▄║├ĄžØMūŃ AI Agent į┌ Branching ╔ŽĄ──▄┴”ąĶŪ¾ĪŻ
ĪĪĪĪ░Ė└²Č■Ż║Į╚┌ąąśI(y©©)░Ė└²
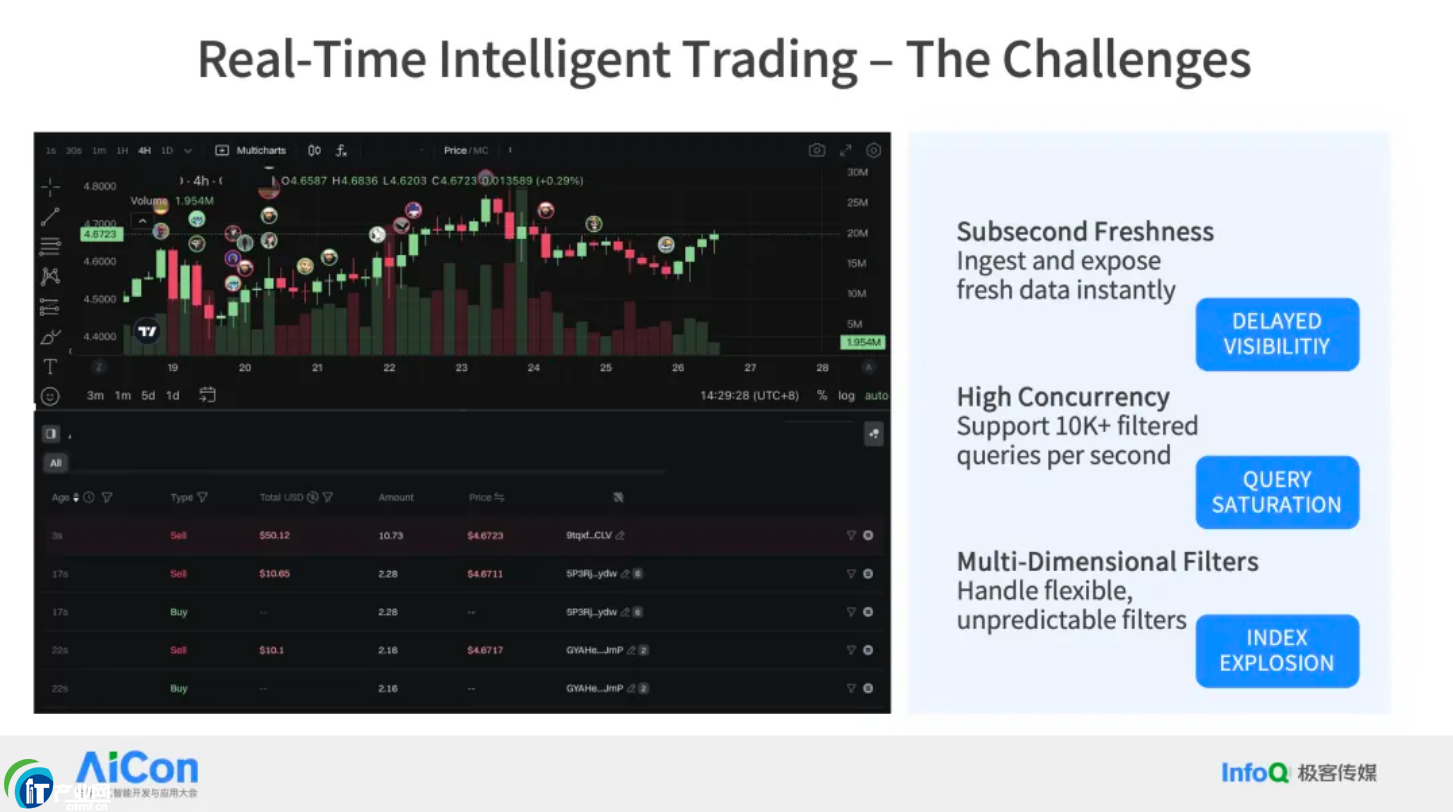
ĪĪĪĪĄ┌Č■éĆ(g©©)░Ė└²╩ŪĮ╚┌ąąśI(y©©)Ą─ę╗éĆ(g©©)ł÷(ch©Żng)Š░Ż¼─Ń┐╔ęį░č╦³└ĒĮŌ×ķę╗éĆ(g©©)Į╗ęūŽĄĮy(t©»ng)ĪŻ▀@éĆ(g©©)ŽĄĮy(t©»ng)Ģ■(hu©¼)Įė╩šĄĮ┤¾┴┐Ą─ąąŪķöĄ(sh©┤)ō■(j©┤)Ż¼▀@ą®öĄ(sh©┤)ō■(j©┤)ąĶę¬į┌┐═æ¶Č╦ęįūŅ┐ņĄ─╦┘Č╚š╣╩Š(Freshness į┌üå├ļ╝ē(j©¬))Ż¼ę“?y©żn)ķ├┐«?d©Īng)ėąę╗éĆ(g©©)Į╗ęū═Ļ│╔║¾Ż¼║¾├µĢ■(hu©¼)ėą┤¾┴┐Ą─ AI ÖC(j©®)Ų„╚╦ū÷Ęų╬÷║═Į╗ęūøQ▓▀ĪŻ╦∙ęįŻ¼öĄ(sh©┤)ō■(j©┤)▌ö╚ļ▒žĒÜ╩Ū Instant Ą─Ż¼ę¬Ū¾“īæ(xi©¦)╚ļ╝┤┐╔ęŖ(ji©żn)”Ż¼▓óŪę▓ķįā┴┐ĘŪ│Ż┤¾ĪŻ┴Ē═ŌŻ¼╦³Ą─▓ķįāę▓▒╚ę╗░ŃĄ─³c(di©Żn)▓ķÅ═(f©┤)ļsĄ─ČÓĪŻ╦³▓╗āHāH╩Ū║å(ji©Żn)å╬Ąž▓ķ┐┤ę╗ąąąąöĄ(sh©┤)ō■(j©┤)Ż¼Č°╩ŪąĶę¬═©▀^(gu©░)┤¾┴┐Ą─ś╦(bi©Īo)║×▀M(j©¼n)ąą▀^(gu©░)×Vū÷ČÓŠSĘų╬÷Ż¼ęį▒Ń─▄ē“ų╗ė^£y(c©©)─│ą®╠žäeĻP(gu©Īn)ūóĄ─ś╦(bi©Īo)║×▓óō■(j©┤)┤╦ū÷│÷øQ▓▀ĪŻ▀@ę▓╩Ū×ķ╩▓├┤╬ęų«Ū░╠ߥĮ┐╔ė^£y(c©©)ąįĄ─ĘČ«ĀĘŪ│Ż┤¾Ż¼Å─└Ēšō╔ŽųvŻ¼▀@ę▓╩Ū┐╔ė^£y(c©©)ąįĄ─ę╗éĆ(g©©)æ¬(y©®ng)ė├ł÷(ch©Żng)Š░ĪŻ
ĪĪĪĪį┌▀@ĘN─▄┴”ę¬Ū¾Ž┬Ż¼é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)─▄ē“ØMūŃĄ─╩Ū Subsecond Level Ą─ą┬§rČ╚║═Ė▀═╠═┬┴┐Ż¼Ą½╦³¤o(w©▓)Ę©ØMūŃČÓŠSĘų╬÷Ą─ąĶŪ¾ĪŻČ° Search ║═ Lakehouse ╝▄śŗ(g©░u)─▄ē“į┌ę╗Č©│╠Č╚╔ŽØMūŃĘų╬÷ąĶŪ¾Ż¼Ą½╦³éā¤o(w©▓)Ę©═¼Ģr(sh©¬)ØMūŃĖ▀═╠═┬┴┐║═Ą═čė▀tĄ─ę¬Ū¾ĪŻ╦∙ęįŻ¼š²╚ń╬ęų«Ū░╦∙šf(shu©Ł)Ż¼Data Warebase Ą─▀@ĘNšµš²Ą─╗ņ║Ž─▄┴”Ż¼ę▓Š═╩ŪČÓ─Ż▓ķįāĄ──▄┴”Ż¼į┌▀@└’Š═’@Ą├ĘŪ│Żųžę¬ĪŻ

ĪĪĪĪ░Ė└²╚²Ż║▄ć(ch©ź)┬ō(li©ón)ŠW(w©Żng)░Ė└²

ĪĪĪĪĄ┌╚²éĆ(g©©)░Ė└²╩Ū▄ć(ch©ź)┬ō(li©ón)ŠW(w©Żng)ĪŻ╬ęéāĮė╚ļ┴╦ę╗éĆ(g©©)Ņ^▓┐Ą─▄ć(ch©ź)┬ō(li©ón)ŠW(w©Żng)ė├æ¶Ż¼╦³Ą─▄ć(ch©ź)ÖC(j©®)ą┼╠¢(h©żo)é„▌öŅl┬╩ĘŪ│ŻĖ▀Ż¼├┐▌v▄ć(ch©ź)├┐├ļČ╝Ģ■(hu©¼)╔Žé„▄ć(ch©ź)ÖC(j©®)ą┼╠¢(h©żo)Ż¼100 ╚f(w©żn)▌v▄ć(ch©ź)Š═ęŌ╬Čų°├┐├ļėą 100 ╚f(w©żn)ŚlöĄ(sh©┤)ō■(j©┤)ė┐╚ļĪŻęį═∙Ż¼▀@ą®öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)üĒ(l©ói)║¾Ż¼╬ęéāų╗╩ŪīóŲõ┤µā”(ch©│)ŲüĒ(l©ói)Ż¼ęįØMūŃ▒O(ji©Īn)╣▄ę¬Ū¾ĪŻĄ½╚ńĮ±Ż¼ļSų°ļŖäė(d©░ng)▄ć(ch©ź)įĮüĒ(l©ói)įĮ╩▄ÜgėŁŻ¼Ūķør░l(f©Ī)╔·┴╦ūā╗»ĪŻ┤¾╝ęČ╝ų¬Ą└Ż¼ļŖäė(d©░ng)▄ć(ch©ź)Ą─ŽĄĮy(t©»ng)╔²╝ē(j©¬)╩Ū═©▀^(gu©░) OTA üĒ(l©ói)īŹ(sh©¬)¼F(xi©żn)Ą─Ż¼Č°▓╗╩ŪŽ±é„Įy(t©»ng)Ų¹▄ć(ch©ź)─ŪśėąĶę¬ķ_(k©Īi)ĄĮ▄ć(ch©ź)ÅSŻ¼▓Õ╔ŽŠĆ▀M(j©¼n)ąą╔²╝ē(j©¬)ĪŻ▀@ą®ļŖäė(d©░ng)▄ć(ch©ź)Ģ■(hu©¼)▓╗öÓĄž═Ų╦═▄ø╝■Ė³ą┬Ż¼Č°▀@ą®▄ø╝■Ė³ą┬┐╔─▄Ģ■(hu©¼)ī”(du©¼)▄ć(ch©ź)ÖC(j©®)«a(ch©Żn)╔·ė░ĒæĪŻ╦∙ęįŻ¼¼F(xi©żn)į┌öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)üĒ(l©ói)ų«║¾Ż¼╬ęéā▀ĆąĶę¬ī”(du©¼)─│ą®ĻP(gu©Īn)µI┴ą▀M(j©¼n)ąąĘų╬÷ĪŻ╝┤╩╣į┌▓╗╔²╝ē(j©¬)Ą─Ģr(sh©¬)║“Ż¼ę▓ąĶę¬ī”(du©¼)║╦ą─▄ć(ch©ź)▌vą┼╠¢(h©żo)ū÷īŹ(sh©¬)Ģr(sh©¬)▒O(ji©Īn)┐žł¾(b©żo)Š»Ż¼┤_▒Ż▄ć(ch©ź)▌v║═▄ć(ch©ź)ų„Ą─░▓╚½ĪŻ
ĪĪĪĪęįŪ░Ą─Ęų╬÷ą═öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)┐╔ęįĮy(t©»ng)ėŗ(j©¼)ę╗ą®Š█║ŽųĄŻ¼Ą½▓╗╔├ķL(zh©Żng)├„╝Ü(x©¼)▓ķįāŻ¼ę“?y©żn)ķ├„╝?x©¼)▓ķįāĄ─Ģr(sh©¬)║“┐╔─▄ąĶę¬ī”(du©¼)ĘŪų„µIūųČ╬ū÷▀^(gu©░)×VŻ¼ąĶ꬚µš²Ą─╚½ŠųČ■╝ē(j©¬)╦„ę²Ż¼Č°▀@ĘN╦„ę²ę╗░Ńę▓ų╗ėą OLTP öĄ(sh©┤)ō■(j©┤)▓┼Š▀ėąĪŻ╦∙ęįŻ¼▀@ĘNł÷(ch©Żng)Š░ĘŪ│Ż▀m║Ž╩╣ė├ČÓ─ŻöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪŻ
ĪĪĪĪ░Ė└²╦─Ż║ÅVĖµ║══Ų╦]░Ė└²

ĪĪĪĪĄ┌╦─éĆ(g©©)░Ė└²╩ŪÅVĖµ║══Ų╦]ĪŻÅVĖµĄ─┴┐▒╚═Ų╦]┤¾Ż¼ę“?y©żn)ķ┤¾▓┐ĘųÅVĖµ╣½╦Š╩š╝»┴╦▒ŖČÓ APP Ą─┴„┴┐Ż¼Ūę├┐┤╬ū÷øQ▓▀Ģr(sh©¬)Ą─▓ķįā▀ē▌ŗę▓▒╚▌^Å═(f©┤)ļsĪŻ«ö(d©Īng)╬ęéā?c©©)┌╩╣ė├Ė„ĘN╩ųÖC(j©®)æ¬(y©®ng)ė├Ģr(sh©¬)Ż¼├┐┤╬╠°▐D(zhu©Żn)ĄĮŽ┬ę╗éĆ(g©©)Įń├µŻ¼ŲõīŹ(sh©¬)Č╝╩Ūę╗éĆ(g©©)øQ▓▀▀^(gu©░)│╠ĪŻ▀@ą®øQ▓▀▀^(gu©░)│╠ųą▓ķįāĄ─öĄ(sh©┤)ō■(j©┤)┴┐ĘŪ│Ż²ŗ┤¾ĪŻ═Ų╦]ŽĄĮy(t©»ng)ę▓╩Ū╚ń┤╦Ż¼¼F(xi©żn)į┌Äū║§╦∙ėąĄ─═Ų╦]ŽĄĮy(t©»ng)Ż¼ė╚Ųõ╩ŪļŖ╔╠ŲĮ┼_(t©ói)Ą─═Ų╦]ŽĄĮy(t©»ng)Ż¼Č╝ąĶꬎÓī”(du©¼)īŹ(sh©¬)Ģr(sh©¬)Ąž▀M(j©¼n)ąąøQ▓▀ĪŻ

ĪĪĪĪ└²╚ńŻ¼«ö(d©Īng)─Ńį┌ļŖ╔╠ŲĮ┼_(t©ói)╔Ž╦č╦„ 1000 į¬Ą─╩ųÖC(j©®)Ģr(sh©¬)Ż¼ŽĄĮy(t©»ng)Ģ■(hu©¼)į┌Ž┬ę╗├ļ×ķ─Ń═Ų╦] 1000 į¬ū¾ėęĄ─╩ųÖC(j©®)Ż¼Č°▓╗╩Ū 1 ╚f(w©żn)į¬Ą─╩ųÖC(j©®)Ż¼ę“?y©żn)ķŽĄĮy(t©»ng)ęčĮø(j©®ng)Ė∙ō■(j©┤)─ŃĄ─╦č╦„ĘČć·ū÷│÷┴╦Š½£╩(zh©│n)Ą─┼ąöÓĪŻī”(du©¼)ė┌ą┬ė├æ¶Ż¼ŽĄĮy(t©»ng)┐╔─▄ę╗ķ_(k©Īi)╩╝ī”(du©¼)─Ń▓╗┴╦ĮŌŻ¼Ą½ę╗Ą®─Ń┘Å(g©░u)┘I(m©Żi)┴╦─│ę╗ŅÉ╦ÄŲĘŻ¼ŽĄĮy(t©»ng)Š═─▄Ė∙ō■(j©┤)▀@ę╗ąą×ķ═ŲöÓ│÷─ŃĄ─┤¾Ė┼─Ļ²gČ╬║═ąįäeŻ¼Å─Č°▀M(j©¼n)ąąéĆ(g©©)ąį╗»═Ų╦]ĪŻ║¾└m(x©┤)Ą─═Ų╦]øQ▓▀Ģ■(hu©¼)ūāĄ├Ė³╝ėĘeśOų„äė(d©░ng)Ż¼▀M(j©¼n)ę╗▓Į╠ß╔²ė├涾w“×(y©żn)ĪŻ▀@ĘNīŹ(sh©¬)Ģr(sh©¬)ąį║═éĆ(g©©)ąį╗»Ą──▄┴”Ż¼╩Ū¼F(xi©żn)┤·═Ų╦]ŽĄĮy(t©»ng)ģ^(q©▒)äeė┌é„Įy(t©»ng)═Ų╦]ŽĄĮy(t©»ng)Ą─ųžę¬╠žš„ĪŻ▀@ĘN═Ų╦]ŽĄĮy(t©»ng)═¼śėąĶę¬īŹ(sh©¬)Ģr(sh©¬)īæ(xi©¦)╚ļŻ¼ŪęĖ▀ŅlĘų╬÷▓ķįāĪŻ
ĪĪĪĪ┐éĮY(ji©”)ę╗Ž┬Ż¼Į±╠ņų„ę¬ĘųŽĒ┴╦į┌ Data for AI Ģr(sh©¬)┤·╬ęė^▓ņĄĮĄ─¼F(xi©żn)Ž¾║═╦╝┐╝Ż¼ęį╝░ Data Warebase Ą─Ė┼─ŅĪŻūŅ║¾Ż¼ĮķĮB┴╦ Data Warebase ╚ń║╬ØMūŃ AI æ¬(y©®ng)ė├į┌ IngestionĪóTransformĪóExplore ║═ Retrieve Ą╚ĘĮ├µĄ─ąĶŪ¾ĪŻ

ĪĪĪĪData Warebase ┼c¼F(xi©żn)ėą╝╝ąg(sh©┤)Ą─▓Ņ«É┼cā×(y©Łu)ä▌(sh©¼)
ĪĪĪĪūŅ║¾į┘║å(ji©Żn)å╬╠ßę╗Ž┬║▄ČÓąĪ╗’░ķ▀^(gu©░)üĒ(l©ói)įāå¢(w©©n) Data Warebase ┼c¼F(xi©żn)ėą╝╝ąg(sh©┤)Ą─▓Ņ«É┼cā×(y©Łu)ä▌(sh©¼)ĪŻ
ĪĪĪĪ1. Data Warebase ┼c HTAP Ą─ģ^(q©▒)äe
ĪĪĪĪ╩ūŽ╚Å─┐═æ¶Ą─ĮŪČ╚üĒ(l©ói)┐┤Ż¼▓╗æ¬(y©®ng)įō│Ż│Żę¬ĻP(gu©Īn)ą─╚źģ^(q©▒)Ęų TP ║═ APŻ¼ę“?y©żn)?SQL ▒Š╔Ē╩Ū─▄īæ(xi©¦)│÷üĒ(l©ói) TP ║═ AP Ą─ Query üĒ(l©ói)Ą─ĪŻų╗╩Ūį┌öĄ(sh©┤)ō■(j©┤)┴┐┤¾Ą─Ģr(sh©¬)║“Ż¼ę╗éĆ(g©©)ŽĄĮy(t©»ng)ę¬├┤╩Ū TP ąį─▄║├ę╗³c(di©Żn)Ż¼ę¬├┤╩Ū AP Ą─ąį─▄Ģ■(hu©¼)║├ę╗³c(di©Żn)ĪŻ╦∙ęį HTAP ę¬Ū¾Ą─╩Ūę╗éĆ(g©©)ŽĄĮy(t©»ng)─▄ē“į┌ TP ł÷(ch©Żng)Š░║═ AP ł÷(ch©Żng)Š░Ž┬ąį─▄Č╝ĘŪ│Ż║├ĪŻ
ĪĪĪĪšµš²Ą─ HTAPŻ¼▓╗ų╣╩Ū║å(ji©Żn)å╬ TP+AP Ą─ĮY(ji©”)║ŽŻ¼Ė³ČÓĄ─╩Ū┤µā”(ch©│)Ż¼╦„ę²Ż¼║═▓ķįāā×(y©Łu)╗»Ų„ę╗¾wĄ─ĮY(ji©”)║ŽĪŻ
ĪĪĪĪŲõ┤╬Ż¼HTAP Ą─║╦ą─į┌ė┌╩Ūʱ─▄šµš²īŹ(sh©¬)¼F(xi©żn) TP ║═ AP Ą─¤o(w©▓)┐p╚┌║ŽĪŻ╚ń╣¹ų╗╩Ūīó TP ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)═¼▓ĮĄĮ AP ŽĄĮy(t©»ng)╚źØMūŃł¾(b©żo)▒Ē▓ķįāŻ¼▀@▓ó▓╗╦Ńšµš²Ą─ HTAPĪŻšµš²Ą─ HTAP ąĶꬊ▀éõęįŽ┬╠ž³c(di©Żn)Ż║
ĪĪĪĪ·šµš²Ą─ HTAP öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)æ¬(y©®ng)įō╝╚─▄¬Ü(d©▓)┴óū„×ķę╗éĆ(g©©) OLTP öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼ę▓─▄¬Ü(d©▓)┴óĄ─ū„×ķę╗éĆ(g©©) OLAP öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ż¼▀Ć─▄ūā│╔ę╗éĆ(g©©)╗ņ║ŽĄ─ HTAP öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĪŻ
ĪĪĪĪ·Ą═čė▀tŻ║öĄ(sh©┤)ō■(j©┤)─▄ē“╝┤Ģr(sh©¬)▀M(j©¼n)╚ļŽĄĮy(t©»ng)Ż¼¤o(w©▓)šōį┌╩▓├┤─Ż╩ĮŽ┬Ż¼öĄ(sh©┤)ō■(j©┤)īæ(xi©¦)╚ļ╝┤┐╔ęŖ(ji©żn)Ż¼▓óŪę┴ó╝┤─▄ē“¤o(w©▓)čė▀tĄ─Ę■äš(w©┤) AP ▓ķįāĪŻ
ĪĪĪĪ·Ė▀═╠═┬Ż║─▄ē“ų¦│ųĖ▀═╠═┬Ą─▓ķįāĪŻ
ĪĪĪĪ·Å═(f©┤)ļs▓ķįāŻ║ų¦│ų═Ļš¹Ą─Å═(f©┤)ļsĄ─ OLAP Ęų╬÷▓ķįāĪŻ
ĪĪĪĪ╚ń╣¹ø](m©”i)ėąÅ═(f©┤)ļs▓ķįāĄ─ąĶŪ¾Ż¼─Ū├┤╗∙▒Š┐╔ęį═©▀^(gu©░)é„Įy(t©»ng)Ą─ TP ŽĄĮy(t©»ng)ĮŌøQĪŻų╗ėąŽ±Į╚┌ąąŪķĘų╬÷▀@śėĄ─ł÷(ch©Żng)Š░Ż¼ąĶę¬öĄ(sh©┤)ō■(j©┤)īŹ(sh©¬)Ģr(sh©¬)īæ(xi©¦)╚ļ║═Ė▀═╠═┬Ą─Å═(f©┤)ļs▓ķįāŻ¼▓┼╩Ūšµš²Ą─ HTAPĪŻData Warebase ę“?y©żn)ķŠ▀ėąąą┴ą╗ņ┤µĄ──▄┴”ęį╝░žSĖ╗Ą─╦„ę²Ż¼╠ņ╚╗Ą─ų¦│ų HTAPŻ¼ė├æ¶ū÷┴╦║Ž└ĒĄ─┤µā”(ch©│)║═╦„ę²Ą─┼õų├║¾Ż¼╦∙ėą▓ķįā SQL Č╝─▄į┌╬’└ĒśOŽ▐╔Ž─├ĄĮūŅĖ▀Ą─═╠═┬║═ūŅĄ═Ą─čė▀tĪŻė├æ¶į┘ę▓▓╗ė├×ķ▓╗═¼ł÷(ch©Żng)Š░Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)▀xą═Č°ō·(d©Īn)ą─ĪŻ
ĪĪĪĪ2. Data Warebase ┼c┴„┼·ę╗¾wĄ─ģ^(q©▒)äe
ĪĪĪĪ┴„┼·ę╗¾wĄ─ĮKśOĮŌĘ©Ż¼▓╗╩Ū FlinkŻ¼Č°╩ŪöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─īŹ(sh©¬)Ģr(sh©¬)į÷┴┐╬’╗»ęĢłDĪŻ
ĪĪĪĪ┴„┼·ę╗¾w╩Ū╬ęéāūŅįńį┌░ó└’╦č╦„ų„╦čĢr(sh©¬)╠ß│÷Ą─Ż¼«ö(d©Īng)Ģr(sh©¬)ė├ Flink ū÷īŹ(sh©¬)Ģr(sh©¬)╠Ä└ĒŻ¼į┘ė├┼·ėŗ(j©¼)╦ŃŻ¼║¾üĒ(l©ói)╬ęéāė├ Flink Ą─┼·╠Ä└ĒĮy(t©»ng)ę╗┴╦┴„║═┼·Ą─ėŗ(j©¼)╦Ń┐“╝▄║═ SQLĪŻĄ½ Flink ▀\(y©┤n)ŠSļyĪó│╔▒ŠĖ▀Ż¼╬ęéāšJ(r©©n)×ķ╬’╗»ęĢłD╩ŪĮŌøQ┴„┼·ę╗¾wĄ─ūŅ╝čĘĮ░ĖĪŻ┤¾▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)ų╗╩Ūų¦│ų╚½┴┐╬’╗»ęĢłD║═ĘŪ│ŻėąŽ▐Ą─į÷┴┐╬’╗»ęĢłD(└²╚ńļp▒ĒĄ─ joinŻ¼┤¾▓┐Ęų?j©½n)?sh©┤)ō■(j©┤)ŽĄĮy(t©»ng)ų╗─▄═©▀^(gu©░)╚½┴┐╬’╗»ęĢłDüĒ(l©ói)ū÷)ĪŻData Warebase īŹ(sh©¬)¼F(xi©żn)┴╦īŹ(sh©¬)Ģr(sh©¬)į÷┴┐╬’╗»ęĢłDŻ¼▀@╩╣Ą├šµš²Ą─┴„┼·ę╗¾wūŅ║å(ji©Żn)å╬Ą─ĘĮ░Ė│╔×ķ¼F(xi©żn)īŹ(sh©¬)ĪŻ

ĪĪĪĪ3. Data Warebase ┼c║■é}(c©Īng)ę╗¾wĄ─ģ^(q©▒)äe
ĪĪĪĪĻP(gu©Īn)ė┌║■é}(c©Īng)ę╗¾wŻ¼║å(ji©Żn)å╬üĒ(l©ói)šf(shu©Ł)Ż¼Š═╩Ūūīé}(c©Īng)║═║■ų«ķgĄ─öĄ(sh©┤)ō■(j©┤)─▄ē“┤“═©Ż¼┴„▐D(zhu©Żn)ŲüĒ(l©ói)Ż¼ūŅĮKūīé}(c©Īng)┐╔ęįų▒ĮėįLå¢(w©©n)║■Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ū÷ę╗ą®▓ķįā╝ė╦┘ĪŻŲõ┤╬ę¬Ū¾öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)─▄ē“?q©▒)”Įėś?bi©Īo)£╩(zh©│n)Ą─║■┤µā”(ch©│)Ż¼ū÷═Ō▒ĒĄ─▓ķįāŻ¼ėŗ(j©¼)╦Ń║═īæ(xi©¦)╚ļĪŻ
ĪĪĪĪäé▓┼ųvĄ─╩ŪöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─┌ģä▌(sh©¼)ĪŻ╚ń╣¹Ę┼┤¾ĄĮ┤¾öĄ(sh©┤)ō■(j©┤)Ą─┌ģä▌(sh©¼)Ż¼ų╗ėąę╗╝■╩┬ųĄĄ├ĻP(gu©Īn)ūóŻ║╬┤üĒ(l©ói)öĄ(sh©┤)ō■(j©┤)║■Ą─ś╦(bi©Īo)£╩(zh©│n)ų╗ėąę╗éĆ(g©©)Ż¼Š═╩Ū IcebergĪŻę“?y©żn)ķ╚½Ū“ā╔┤¾ö?sh©┤)ō■(j©┤)Š▐Ņ^ Snowflake ║═ Databricks Č╝į┌ć·└@ Iceberg š╣ķ_(k©Īi)ĪŻSnowflake Ą─┤µā”(ch©│)ę╗ķ_(k©Īi)╩╝Š═╩Ū╗∙ė┌ Iceberg įO(sh©©)ėŗ(j©¼)║═īŹ(sh©¬)¼F(xi©żn)Ą─Ż¼Databricks ų«Ū░ėąūį蹥─ Delta LakeŻ¼║¾üĒ(l©ói)╩š┘Å(g©░u)┴╦ Iceberg ▒│║¾Ą─╣½╦Š TabularĪŻ╦∙ęį╬ęéā┐╔ęįŅA(y©┤)ęŖ(ji©żn)Ż¼╬┤üĒ(l©ói)▀@ā╔éĆ(g©©)╩└ĮńūŅ┤¾Ą─öĄ(sh©┤)ō■(j©┤)Š▐Ņ^Č╝Ģ■(hu©¼)ć·└@ų° Iceberg üĒ(l©ói)▓╝Šų?j©½n)?sh©┤)ō■(j©┤)║■╔·æB(t©żi)ĪŻ
ĪĪĪĪĮY(ji©”) šZ(y©│)
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)║═┤¾öĄ(sh©┤)ō■(j©┤)č▌▀M(j©¼n)ĄĮ Data WarebaseŻ¼▓╗ų╗╩Ū╝▄śŗ(g©░u)Ė’ą┬Ż¼Ė³╩Ū×ķ AI ╣żū„┴„┤“Ž┬łį(ji©Īn)īŹ(sh©¬)Ą─öĄ(sh©┤)ō■(j©┤)Ąūū∙ĪŻį┌ą┬ę╗▌åĄ─ AI └╦│▒ųąŻ¼šl(shu©¬)ōĒėąĖ³═Ļš¹Ė³ÅŖ(qi©óng)┤¾Ą─ Data APIŻ¼šl(shu©¬)Š═ōĒėąĖ³Ė▀Ą─ųŪ─▄╔ŽŽ▐ĪŻ
ĪĪĪĪū„š▀║å(ji©Żn)ĮķŻ║
ĪĪĪĪ═§ĮB┬QŻ¼ProtonBase äō(chu©żng)╩╝╚╦╝µ CEOĪŻį°į┌ Facebook žō(f©┤)ž¤(z©”)į┌ŠĆ╗∙ĄA(ch©│)įO(sh©©)╩®ķ_(k©Īi)░l(f©Ī)Ż¼▓ó╔ŅČ╚ģó┼c┴╦ MemcacheŻ¼RocksDB ║═ūįčąĘų▓╝╩ĮłDöĄ(sh©┤)ō■(j©┤)Äņ(k©┤) TAO Ą─ķ_(k©Īi)░l(f©Ī)Ż¼įōöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ų¦ō╬┴╦ Facebook ├┐├ļÄū╩«ā|┤╬Ą─║Ż┴┐öĄ(sh©┤)ō■(j©┤)▓ķįāĪŻ2015 ─Ļ╝ė╚ļ░ó└’░═░═Ż¼Ž╚║¾žō(f©┤)ž¤(z©”)ā╔ĒŚ(xi©żng)║╦ą─╣żū„Ż║ę╗╩Ūė├ Flink ┤“įņ┴╦╦č╦„═Ų╦]ŽÓĻP(gu©Īn)Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē┼c AI ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)ŲĮ┼_(t©ói)Ż¼Č■╩Ūžō(f©┤)ž¤(z©”)▀_(d©ó)─”į║ÖC(j©®)Ų„ųŪ─▄╣ż│╠łF(tu©ón)ĻĀ(du©¼)Ż¼░³└©ęĢėX(ju©”) / šZ(y©│)ę¶ /NLP Ą╚ AI ł÷(ch©Żng)Š░Ą──Żą═ė¢(x©┤n)ŠÜŻ¼═Ų└ĒŻ¼ęį╝░Ž“┴┐Öz╦„╝╝ąg(sh©┤)ĪŻ2021 ─Ļķ_(k©Īi)╩╝äō(chu©żng)śI(y©©)Ż¼äō(chu©żng)┴ó“ąĪ┘|(zh©¼)┐Ų╝╝”Ż¼═Ų│÷┴╦ūįčą«a(ch©Żn)ŲĘ ProtonBaseŻ¼ę╗┐Ņ╚┌║ŽöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)┼cöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)─▄┴”ė┌ę╗¾wĄ─ą┬ę╗┤· Data Warebase(Data Warehouse + Database)ĪŻ

ĪĪĪĪąąśI(y©©)┘YėŹĪóŲ¾śI(y©©)äė(d©░ng)æB(t©żi)ĪóśI(y©©)Įńė^³c(di©Żn)ĪóĘÕĢ■(hu©¼)╗Ņäė(d©░ng)┐╔░l(f©Ī)╦═Ó]╝■ų┴news#citmt.cnŻ©░č#ōQ│╔@Ż®ĪŻ
║Żł¾(b©żo)╔·│╔ųą...
ūų╚╦ūóāį(c©©)├Ō┘M(f©©i)įćė├")
æ¶")