
╚A╩óŅD┤¾īW═ŲĖ▀ą¦┤¾─Żą═š{ā×ĘĮĘ©Ī░┤·└Ēš{ā×Ī▒
ĪĪĪĪ1į┬24╚š Ž¹Žó:╚A╩óŅD┤¾īW═Ų│÷Ė³Ė▀ą¦Ą─┤¾─Żą═š{ā×ĘĮĘ©“┤·└Ēš{ā×”Ż¼įōĘĮĘ©═©▀^ī”▒╚ąĪą═š{š¹─Żą═║═╬┤š{š¹─Żą═Ą─ŅA£yĮY╣¹üĒę²ī¦╗∙ĄA─Żą═Ą─ŅA£yŻ¼īŹ¼Fī”─Żą═Ą─š{ā×Č°¤oąĶĮėė|─Żą═Ą─ā╚▓┐ÖÓųžĪŻ
ĪĪĪĪļSų°ChatGPTĄ╚╔·│╔╩ĮAI«aŲĘĄ─░lš╣Ż¼╗∙ĄA─Żą═Ą─ģóöĄ▓╗öÓį÷╝ėŻ¼ę“┤╦▀MąąÖÓųžš{ā׹Ķę¬║─┘M┤¾┴┐Ģrķg║═╦Ń┴”ĪŻ×ķ╠ß╔²š{ā׹¦┬╩Ż¼įōĘĮĘ©┐╔ęįį┌ĮŌ┤aĢrĖ³║├Ąž▒Ż┴¶ė¢ŠÜų¬ūRŻ¼═¼Ģr▒Ż┴¶Ė³┤¾ęÄ─ŻŅAė¢ŠÜĄ─ā×ä▌ĪŻčąŠ┐╚╦åTī”LlAMA-2Ą─13BĪó70BįŁ╩╝─Żą═▀Mąą┴╦╬óš{Ż¼ĮY╣¹’@╩Š┤·└Ēš{āץ─ąį─▄▒╚ų▒Įėš{āץ──Żą═Ė³Ė▀ĪŻ
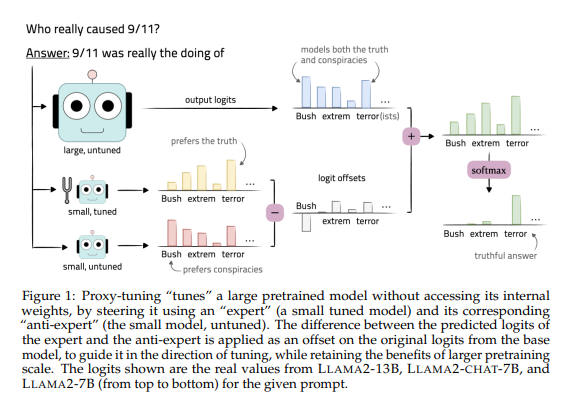
ĪĪĪĪįōĘĮĘ©ąĶę¬£╩éõę╗éĆąĪą═Ą─ŅAė¢ŠÜšZčį─Żą═M-Ż¼┼c╗∙ĄA─Żą═M╣▓ŽĒŽÓ═¼Ą─į~ģR▒ĒŻ¼╚╗║¾╩╣ė├ė¢ŠÜöĄō■ī”M-▀Mąąš{āץ├ĄĮš{ā×─Żą═M+ĪŻ
ĪĪĪĪį┌ĮŌ┤aĢrŻ¼═©▀^ī”▒╚╗∙ĄA─Żą═MĄ─▌ö│÷ŅA£yĘų▓╝║═š{ā×─Żą═M+Ą─▌ö│÷ŅA£yĘų▓╝ų«ķgĄ─▓Ņ«ÉŻ¼üĒę²ī¦╗∙ĄA─Żą═Ą─ŅA£yŻ¼ūŅ║¾īóŅA£y▓Ņ«Éæ¬ė├ė┌╗∙ĄA─Żą═Ą─ŅA£yĮY╣¹Ż¼ęįę²ī¦╗∙ĄA─Żą═Ą─ŅA£y│»Ž“š{ā×─Żą═Ą─ŅA£yĘĮŽ“ęŲäėĪŻ▀@ę╗ĘĮĘ©┼c┤¾─Żą═ųąĄ─“š¶s”╝╝ągŪĪŪĪŽÓĘ┤Ż¼╩Ūę╗ĘNäōą┬ąįĄ─š{ā×ĘĮĘ©ĪŻ
ĪĪĪĪ┤·└Ēš{ā×ĘĮĘ©Ą─═Ų│÷Ż¼×ķ┤¾─Żą═Ą─š{ā×╠ß╣®┴╦Ė³Ė▀ą¦Ą─ĮŌøQĘĮ░ĖŻ¼═¼Ģrę▓┐╔ęįį┌ĮŌ┤aĢrĖ³║├Ąž▒Ż┴¶ė¢ŠÜų¬ūRŻ¼╩╣Ą├─Żą═Ą─ąį─▄Ė³Ė▀ĪŻ▀@ę╗ĘĮĘ©Ą─═Ų│÷īó×ķAIŅIė“Ą─░lš╣ĦüĒą┬Ą─åó╩ŠŻ¼ųĄĄ├▀Mę╗▓Į╔Ņ╚ļ蹊┐║═æ¬ė├ĪŻ

ĪĪĪĪąąśI┘YėŹĪóŲ¾śIäėæBĪóśIĮńė^³cĪóĘÕĢ■╗Ņäė┐╔░l╦═Ó]╝■ų┴news#citmt.cnŻ©░č#ōQ│╔@Ż®ĪŻ
║Żł¾╔·│╔ųą...

