
Į³Ų┌┬ĀĄĮĻPė┌ GEO ūŅ═ĖÅžĄ─šJų¬
ĪĪĪĪĮ±─Ļ,GEO ╠žäe¤ßĪŻ
ĪĪĪĪ─ĻĄū┴╦,╔Žų▄║══¼╩┬ęŖ┴╦ā╔▓©īŻū÷ GEO Ą─łFĻĀ,─├ĄĮę╗ą®ūŅą┬Ą─ąąśIšJų¬ĪŻĮ±╠ņīæŲ¬╬─š┬üĒĘųŽĒŽ┬ĪŻ
ĪĪĪĪ╬ęéāČ╝─▄ĖąėXĄĮ,ė├æ¶Ą─┴ĢæTį┌┐ņ╦┘ūā╗»ĪŻŽ±╬ęęįŪ░šęą┼ŽóĢ■┴ĢæT┤“ķ_╣╚ĖĶ╗“░┘Č╚,▌ö╚ļĻPµIį~▓ķšęī”æ¬Ą─┐╔─▄├³ųą┤░ĖĄ─ŠWĒōĪŻĄ½¼Fį┌,╬ęät╩ŪęčĮøÅžĄū┴ĢæT┼▄ĄĮ ChatGPT ų«ŅÉĄ─ AI æ¬ė├ųą,ė├ūį╚╗šZčįĄ─ĘĮ╩Į├Ķ╩÷å¢Ņ},╦¹éāĢ■ų▒ĮėĮo│÷üĒ╬ęéā┤░ĖĪŻ
ĪĪĪĪ░³└©░┘Č╚Īó╣╚ĖĶ▀@śė╦č╦„«aŲĘ,╦¹éāę▓Č╝╝ė┴╦ AI ─Ż╩ĮĪŻ▀@╩Ūę╗éĆ╝╚Č©Ą─┌ģä▌ĪŻ
ĪĪĪĪ1
ĪĪĪĪ▀^╚ź╩«ČÓ─ĻĢrķg,SEO ╩Ū╗ź┬ōŠWĄ─ųžę¬ūhŅ}ĪŻę“×ķ«ö╦č╦„│╔×ķė├æ¶Ą─╚ļ┐┌ų«║¾,┤¾╝ęŽļ½@Ą├┴„┴┐,Š═ąĶꬎļ▒M▐kĘ©─▄ūīūį╝║Ą─«aŲĘŠWšŠ┐┐Ū░ĪŻ
ĪĪĪĪĄ½¼Fį┌,║┴¤oę╔å¢,SEO Ą─ÖÓųžį┌ĮĄĄ═ĪŻ╚ĪČ°┤·ų«Ą─╩Ū GEO(Generative Engine Optimization)ĪŻę▓ėą╚╦░č GEO ĘQų«×ķ AEO(Answer Engine Optimization)ĪŻ▓╗╝mĮYĖ┼─Ņ,╦¹éāšfĄ─Č╝╩Ūę╗╗ž╩┬ĪŻ
ĪĪĪĪGEO ▒Š┘|╩Ūūī«aŲĘį┌┤¾─Żą═Ą─┤░Ė└’▒╗╠ߥ├Ė³ČÓĪŻ
ĪĪĪĪ┤¾─Żą═į┌╗ž┤å¢Ņ}Ģr,▓╗į┘╩ŪÅ──│ę╗Ų¬ŠWĒō└’š¬ę╗Č╬,Č°╩ŪĢ■░č╚½ŠW║═šZŠ│ŽÓĻPĄ─ā╚╚▌ę╗Ų┐┤,╚╗║¾ųžą┬ĮM┐Ś│╔ę╗ŠõĒśĢ│Ą─╗ž┤ĪŻ
ĪĪĪĪ╦³Ģ■Ž╚└ĒĮŌå¢Ņ}Ą─ęŌłD,į┘į┌ūį╝║Ą─ų¬ūRĘČć·└’šę│÷─▄ē“ĮŌßī▀@éĆå¢Ņ}Ą─ūCō■,ūŅ║¾░č▀@ą®ūCō■š¹└Ē│╔ę╗Šõūį╚╗šZčįĄ─┐éĮYĪŻ
ĪĪĪĪ▀@ę▓ĦüĒ┴╦ę╗éĆ║▄ų▒ĮėĄ─ĮY╣¹:
ĪĪĪĪšlį┌─Żą═─▄┐┤ĄĮĄ─ā╚╚▌╩└Įń└’│÷¼FĄ├ČÓ,šl▒╗╠ߥĮĄ─┤╬öĄĘĆČ©,šlĄ─ā╚╚▌┼cų„Ņ}ĻP┬ōČ╚Ė³Ė▀,šlŠ═Ė³╚▌ęū▀M╚ļūŅ║¾Ą─┤░Ė└’ĪŻ
ĪĪĪĪ▀@Š═╩Ū GEO Ą─Ų³c,ę▓╩Ū╦³į┌▀@éĆļAČ╬═╗╚╗ūāĄ├ųžę¬Ą─Ė∙▒ŠįŁę“ĪŻ
ĪĪĪĪ╚ń╣¹ė├Ė³║åØŹĄ─ĘĮ╩ĮĮŌßī:SEO ĻPūóĄ─╩Ūā╚╚▌┼┼į┌Ą┌ÄūĪŻGEO ĻPūóĄ─╩Ūā╚╚▌Ģ■▓╗Ģ■▒╗─Żą═─├üĒĘ┤Å═╩╣ė├ĪŻę╗éĆ╩Ū┼┼├¹å¢Ņ},ę╗éĆ╩Ūę²ė├å¢Ņ}ĪŻ
ĪĪĪĪ┤¾─Żą═āAŽ“Å═ė├─Ūą®ą┼ŽóĖ³═Ļš¹ĪóĖ▓╔wČ╚Ė³Ė▀Īóį┌ŽÓĻPų„Ņ}└’│÷¼FŅlĘ▒Ą─ā╚╚▌,Č°▓╗╩ŪĒō├µū÷Ą├Ė³╚A¹ÉĄ─ā╚╚▌ĪŻ
ĪĪĪĪ▒╚╚ńę╗éĆ«aŲĘĮ╠│╠,╚ń╣¹ų╗ųv┴╦╗∙ĄA╣”─▄,─Żą═Ģ■ėXĄ├ą┼Žóį÷┴┐ėąŽ▐,─Ū╦³ę²ė├─ŃĄ─Ė┼┬╩Ģ■├„’@Ž┬ĮĄĪŻĄ½╚ń╣¹─ŃĄ─ā╚╚▌Ė▓╔w┴╦ė├æ¶Ģ■å¢Ą─ķL╬▓å¢Ņ},ĮŌßī┴╦▒│║¾Ą─įŁę“,ėą▀B└mĄ─╔ŽŽ┬╬─,╔§ų┴ėąšµīŹė├æ¶ėæšō,─Żą═Ģ■Ė³įĖęŌĘ┤Å═─├üĒ«öūCō■į┤ĪŻ
ĪĪĪĪ└ĒĮŌ┴╦ GEO Ą─Ąūīė▀ē▌ŗų«║¾,å¢Ņ}ūāĄ├ĘŪ│Ż¼FīŹ:╝╚╚╗─Żą═┐┤Ą─╩Ūę²ė├,─Ū╬ęéāĄĮĄūįōį§├┤▐k,─Żą═▓┼Ė³įĖęŌę²ė├╬ęéāĪŻ
ĪĪĪĪ▀^╚źū÷ SEO,▒Š┘|╔Ž╩Ūć·└@╦č╦„ę²ŪµĄ─ęÄätüĒš{š¹ā╚╚▌,ūī╦ŃĘ©Ė³╚▌ęūūRäe╬ęéāĪó└ĒĮŌ╬ęéāĪó░č╬ęéā┼┼į┌Ū░├µĪŻ
ĪĪĪĪĄ½ GEO ├µŽ“Ą─╩Ū┤¾─Żą═ĪŻ─Żą═▓╗░┤ĻPµIį~šę,╦³░┤šZ┴x└ĒĮŌ;─Żą═▓╗┐┤å╬ĒōÖÓųž,╦³┐┤Ą─╩Ū╚½ė“ą┼ŽółDūVĪŻ╦³▓╗į┌║§Ēō├µ╩ŪʱŠ½ą▐,Č°į┌║§─Ń─▄▓╗─▄šµš²ĮŌßīę╗éĆų„Ņ}ĪŻ
ĪĪĪĪ2
ĪĪĪĪ─┐Ū░ GEO ļm╚╗▀Ćį┌įńŲ┌,Ą½ąąśI└’Įø▀^“×ūC,šµš²ėąą¦Ą─ū÷Ę©ęčĮøķ_╩╝╩šö┐│╔╚²ŚlŠĆĪŻ
ĪĪĪĪĄ┌ę╗ŚlŠĆ:░č╗∙ĄAā╚╚▌ū÷į·īŹĪŻ
ĪĪĪĪ┤¾─Żą═Ą─ķåūxĘĮ╩Į║═╚╦═Ļ╚½▓╗ę╗śė,╦³Ģ■░čā╚╚▌▓│╔ęŌ┴xå╬į¬,╚ź┼ąöÓ▀@éĆĒō├µĄĮĄū─▄▓╗─▄Ä═╦³ĮŌßīę╗éĆå¢Ņ}ĪŻ╚ń╣¹ų╗ėąÄūŠõĖ┼─ŅąįĄ─ĮķĮB,╦³Ģ■ų▒Įė╠°▀^,ę“×ķą┼Žó├▄Č╚╠½Ą═,╦³Å─ųąĄ├▓╗ĄĮ╚╬║╬į÷┴┐ĪŻ
ĪĪĪĪĘ┤▀^üĒ,«öę╗éĆų„Ņ}▒╗▓ķ_ųvŪÕ│■Ģr,─Żą═Ą─Ę┤æ¬ĘŪ│Ż├„’@ĪŻ
ĪĪĪĪ▒╚╚ńę╗éĆ╣”─▄×ķ╩▓├┤▀@śėįOėŗ,╩╣ė├▀^│╠ųą┐╔─▄ė÷ĄĮ╩▓├┤Ūķør,═¼ŅÉ«aŲĘĄ─▓Ņäeį┌──,ė├æ¶│ŻęŖĄ─└¦╗¾╩Ū╩▓├┤,▀@ą®Č╝ī┘ė┌Ė▀ārųĄĄ─šZ┴xŲ¼Č╬ĪŻ─Żą═Ģ■░č╦³éā«ö│╔Ė³┐╔┐┐Ą─ūCō■,ę“×ķ▀@ą®ā╚╚▌į┌äe╠Ä▓╗╚▌ęūšęĄĮ,ę▓─▄Ä═ų·╦³Ė³═Ļš¹Ąž╗ž┤å¢Ņ}ĪŻ
ĪĪĪĪįĮ╩Ū─▄ĮŌßī▀ē▌ŗĪóįĮ╩Ū─▄Ė▓╔wķL╬▓ł÷Š░ĪóįĮ╩Ū─▄░čĄūīėįŁę“ųv═ĖĄ─ā╚╚▌,▒╗─Żą═ę²ė├Ą─Ė┼┬╩įĮĖ▀ĪŻ─Żą═Ų½║├ĦĮYśŗĪóėąę“╣¹Īóėą▒│Š░Īóėą╔ŽŽ┬╬─Ą─ā╚╚▌,ę“×ķ╦³─▄Å─ųą▓Č½@ĄĮšµīŹĄ─šZ┴xĻPŽĄ,Č°▓╗╩Ū┐šČ┤Ą─├Ķ╩÷ĪŻ
ĪĪĪĪę╗éĆČ┤▓ņ╩Ū,─Żą═▓╗āHį┌šę“╩Ū╩▓├┤”,Ė³╩Ūį┌šę“×ķ╩▓├┤”║═“į§├┤ė├”ĪŻ
ĪĪĪĪ╚ń╣¹╗∙ĄAā╚╚▌└’ėą«aŲĘ╩╣ė├Ą─üĒ²ł╚ź├},ėąįOėŗ▒│║¾Ą─┐╝┴┐,ėąīŹļH▓┘ū„ĢrĄ─╝Ü╣Ø,ėąÅ─ł÷Š░│÷░lĄ─ĮŌßī,─Żą═Ģ■ūį╚╗░č▀@ą®ą┼Žó«ö│╔┐╔ęįÅ═ė├Ą─╣سcĪŻ╦³▓╗╩Ū░čā╚╚▌Å═ųŲ▀^╚ź,Č°╩Ū░čā╚╚▌▓│╔ų¬ūR,▓óį┌║¾└m╗ž┤ųąĘ┤Å═š{ė├ĪŻ
ĪĪĪĪĄ┌Č■ŚlŠĆ:šµīŹĄ─ėæšō║▄ųžę¬ĪŻ
ĪĪĪĪ─Żą═į┌╠Ä└Ēā╚╚▌Ģr,ėąę╗ŅÉą┼ŽóÖÓųž╠žäeĖ▀,Š═╩ŪüĒūįšµīŹėæšōĄ─šZ┴ŽĪŻę“×ķ▀@└’├µ╠ņ╚╗Ħų°ŪķŠ│ĪóūĘå¢Īóę╔╗¾ĪóĀÄšōĪóĘ┤ī”Īó│╬ŪÕ,▀@ą®Č╝╩Ūūį╚╗šZčįūŅļyé╬įņę▓ūŅėąārųĄĄ─▓┐ĘųĪŻ
ĪĪĪĪŽÓ▒╚╣┘ŠWĮķĮB─ŪĘNå╬Ž“ĻÉ╩÷,šµīŹėæšō░³║¼┴╦žSĖ╗Ą─šZ┴xŠĆ╦„,─▄ūī─Żą═▓ČūĮĄĮĖ³╝ė╝Üų┬Ą─└ĒĮŌĘĮ╩ĮĪŻ
ĪĪĪĪć°═Ōū÷ GEO Ą─łFĻĀų«╦∙ęįÄū║§Č╝Čóų° Reddit,▓╗╩Ūę“×ķ Reddit ┴„┴┐┤¾,Č°╩Ūę“×ķ Reddit Ą─ā╚╚▌ą╬æBī”─Żą═╠žäeėč║├ĪŻę╗éĆįÆŅ}═∙═∙Å─ę╗éĆ║åå╬╠ßå¢ķ_╩╝,ĮėŽ┬üĒĢ■ėąĖ„ĘNĮŪČ╚Ą─╗ž┤,├┐éĆ╗ž┤ėų┐╔─▄▒╗ūĘå¢Īóča│õĪóĘ┤±gĪŻ
ĪĪĪĪ«öę╗éĆų„Ņ}į┌šµīŹėæšō└’│÷¼FĄ├ūŃē“ČÓĢr,─Żą═Š═─▄ĮĶų·▀@ą®ėæšōą╬│╔ī”▀@éĆų„Ņ}Ą─šµš²└ĒĮŌĪŻ╦³▓╗āHų¬Ą└▒Ē├µĄ─╣”─▄├Ķ╩÷,▀Ć─▄ų¬Ą└╩╣ė├ĢrĄ─╝Ü╣ØĪóė├æ¶Ą─ŪķŠwĪó▓╚┐ėĄ─Įø▀^Īó▓╗═¼ł÷Š░Ą─▓Ņ«ÉĪóĖ„ĘNū÷Ę©Ą─└¹▒ūĪŻ
ĪĪĪĪ▀@ą®Č╝╩Ū─Żą═ūŅ╚▒Ą─ęĢĮŪĪŻ
ĪĪĪĪĄ┌╚²ŚlŠĆ:ČÓį¬Ą─ā╚╚▌Ė▓╔wĪŻ
ĪĪĪĪ─Żą═į┌╔·│╔┤░ĖĢr,Ģ■═¼ĢrÅ─║▄ČÓüĒį┤šęūCō■,╦³▓╗Ģ■ę└┘ćę╗éĆĒō├µ,ę▓▓╗Ģ■ų╗┐┤─│éĆŲĮ┼_ĪŻ╦³Ą─▀^│╠Ė³Ž±╩Ūį┌Ų┤ę╗Ę∙┤¾łD,ŲĘ┼ŲĄ─┤µį┌Ėą▓╗╩Ū═©▀^─│ę╗┤╬│÷¼FĮ©┴óĄ─,Č°╩Ū═©▀^į┌▓╗═¼šZŠ│Īó▓╗═¼ĮŪČ╚Īó▓╗═¼ā╚╚▌ŅÉą═└’│ų└mŲž╣Ō└█ĘeŲüĒĄ─ĪŻ
ĪĪĪĪąąśI└’ęčĮøėąįĮüĒįĮČÓĄ─└²ūė┐╔ęįūC├„,GEO Ą─ųž³c▓╗╩ŪŲž╣Ō┴┐▒Š╔Ē,Č°╩Ū░čā╚╚▌Ę┼į┌─Żą═─▄ē“ūź╚ĪĄ─ĄžĘĮĪŻ
ĪĪĪĪ╔ŅČ╚╬─š┬ĪóąąśIė^³cĪó├Į¾wł¾Ą└Īó░Ė└²▓ĮŌĪó╝╝ągĘų╬÷Īó«aŲĘ╣╩╩┬,▀@ą®ą╬╩Į╣▓═¼śŗ│╔┴╦ę╗éĆų„Ņ}Ą─▒│Š░ų¬ūR,Č°▒│Š░ų¬ūRŪĪŪĪ╩Ū─Żą═╗ž┤å¢Ņ}ĢrūŅ│Ż▒╗ę²ė├Ą─▓┐ĘųĪŻ
ĪĪĪĪ«öę╗éĆįÆŅ}▒╗╠ßŲĢr,─Żą═Ģ■ūįäėīżšę╦³╩ņŽżĄ─ūCō■ĪŻ╚ń╣¹─Ńį┌▓╗═¼ŅÉą═Ą─ā╚╚▌└’Ę┤Å═▒╗╠ߥĮ,¤ošō╩Ūė^³cĪóĮø“×ĪóĘų╬÷▀Ć╩Ū░Ė└²,╦³Č╝Ģ■░č─ŃęĢ×ķ▀@éĆįÆŅ}Ą─ę╗▓┐Ęų,Č°▓╗╩Ū┼╝Ā¢│÷¼FĄ─³cĪŻ╠žäe╩Ū«ö▀@ą®ā╚╚▌üĒūį▓╗═¼ŲĮ┼_Īó▓╗═¼ąąśI├Į¾wĪó▓╗═¼šZŠ│Ģr,─Ńį┌─Żą═ų¬ūRŠWĮj└’Ą─├▄Č╚Ģ■’@ų°╠ß╔²ĪŻ
ĪĪĪĪĮø▀^“×ūC,īŻśI▓®┐═Īó├Į¾w╔ŅČ╚ĖÕĪóÖÓ═■Ęų╬÷ł¾Ėµ,═∙═∙╩Ū─Żą═ĘŪ│Żę└┘ćĄ─ą┼Žóį┤ĪŻ╦³éā╠ß╣®Ą─▓╗╩Ū╦ķŲ¼,Č°╩ŪĮYśŗ╗»Ą─▒│Š░,║▄ČÓĢr║“╩Ū─Żą═ĮM┐Ś┤░ĖĄ─Ąūū∙ĪŻ▀@ŅÉā╚╚▌│÷¼FĄ├įĮČÓ,▒╗ę²ė├Ą─ÖCĢ■įĮ┤¾ĪŻ
ĪĪĪĪ3
ĪĪĪĪŪ░├µĄ─Ą┌ę╗ŚlŠĆ║═Ą┌╚²ŚlŠĆ,ŲõīŹū÷▀^ SEO Ą─═¼īWĢ■║▄╩ņŽżĪŻ
ĪĪĪĪā╚╚▌ę¬ū÷į·īŹ,ę¬░č«aŲĘŽÓĻPĄ─ų„Ņ}Č╝īæŪÕ│■,▀@ę╗ēK┐╔ęįģó┐╝³SĮłAŁh─Żą═ĪŻ═¼Ģrę▓ąĶę¬į┌╔ŅČ╚├Į¾w║═ĻPµIŪ■Ą└└’▒Ż│ųĘĆČ©Ą─ā╚╚▌Ė▓╔w,ūī─Żą═─▄ē“į┌▓╗═¼üĒį┤└’Č╝─▄ė÷ĄĮ«aŲĘĪŻ
ĪĪĪĪ▀@ā╔Śl,╬ęų¬Ą└ųžęĢ GEO Ą─═¼īW╗∙▒ŠČ╝į┌ū÷ĪŻ
ĪĪĪĪę“×ķ▀@ą®ū÷Ę©Ą─╦╝┬Ę║═▀^╚ź SEO Ą─Ąūīė▀ē▌ŗėąę╗Č©čė└m,ų╗▓╗▀^Å─ā×╗»Ēō├µ,ūā│╔┴╦ūīā╚╚▌Ė³ŪÕ╬·ĪóĖ³ĮYśŗ╗»,─▄ūī─Żą═Ė³╚▌ęūūxČ«║═ę²ė├ĪŻ▀@ą®┬ĘÅĮ,┤¾ČÓöĄłFĻĀæ¬įōČ╝─▄ūį╚╗ęŌūRĄĮę¬╚źū÷ĪŻ
ĪĪĪĪĄ½Ą┌Č■ŚlŠĆ═Ļ╚½▓╗ę╗śėĪŻ
ĪĪĪĪ╦³Ą─║╦ą─▓╗į┌ŲĘ┼Ųūį╝║īæ┴╦╩▓├┤,Č°į┌ė├æ¶į§├┤┴─ĪŻ╦³ę▓▓╗┐┤─│ę╗Ų¬ā╚╚▌īæĄ├ČÓ║├,Č°╩Ū┐┤š¹Ślėæšō└’Ą─╚╦į§├┤üĒ╗žĮ╗┴„ĪŻ
ĪĪĪĪ║▄ČÓĢr║“,─Ūą®Ä¦ų°ŪķŠwĪóĦų°╝Ü╣ØĪóĦų°ł÷Š░Ą─▒Ē▀_,─Żą═Ę┤Č°Ė³įĖęŌė├ĪŻ
ĪĪĪĪ╬ę║═ÄūéĆū÷ GEO Ą─┼¾ėčĮ╗┴„,╦¹éāę╗ų▒šJ×ķ:šµīŹĄ─ėæšōøQČ©┴╦ę╗éĆŲĮ┼_į┌ GEO ļAČ╬─▄▓╗─▄│╔×ķĻPµI╣سc,ę▓øQČ©┴╦─Żą═šµš²ą┼╚╬Ą─šZčįĮYśŗüĒūį──└’ĪŻ
ĪĪĪĪ▀@ę▓╩Ū×ķ╩▓├┤į┌║Ż═Ō,Reddit Ģ■│╔×ķ AEO ▓▀┬į└’Ą─║╦ą─╬╗ų├ĪŻ
ĪĪĪĪReddit Ą─ėæšōī”─Żą═üĒšf▓╗╩Ūā╚╚▌,Č°╩ŪšZ┴ŽĪŻ╦³╠ņ╚╗Š▀éõ─Żą═ąĶꬥ─Äū╝■╩┬:ČÓ▌åī”įÆĪóšµīŹšZÜŌĪóķL╬▓å¢Ņ}Īół÷Š░╝Ü╣ØĪŻ
ĪĪĪĪę╗éĆ╠¹ūėŽ┬├µÄū╩«╔Ž░┘Śl╗žÅ═,░čę╗éĆå¢Ņ}Å─▓╗═¼ĮŪČ╚▓ķ_Īó┼÷ū▓Īóča│õĪóĘ┤▐D,▀@ĘN├▄Č╚ų╗ėąšµīŹėæšō─▄ĮoĪŻČ°┤¾─Żą═└ĒĮŌę╗éĆų„Ņ},┐┐Ą─š²╩Ū▀@ĘNšµīŹšZŠ│ĪŻ
ĪĪĪĪĄ½ųą╬─╗ź┬ōŠW─ž?ėąø]ėąŅÉ╦Ų Reddit Ą─ŲĮ┼_?
ĪĪĪĪėą,Ą½▓╗╩Ūų¬║§,ę▓▓╗╩Ū╬ó▓®ĪŻų¬║§¼Fį┌ęčĮøø]╩▓├┤Ė▀┘|┴┐Ą─ėæšō,║▄ČÓČ╝į┌╣Ó╦«,Č°╬ó▓®,╦³Ą─ėæšōėų╦ķĪŻ
ĪĪĪĪų╗ėąę╗éĆĄžĘĮĄ─ĮYśŗ┼cšZ┴Ž╠žš„║═ Reddit Ė▀Č╚ŅÉ╦Ų,─ŪŠ═╩Ū░┘Č╚┘N░╔ĪŻ
ĪĪĪĪ4
ĪĪĪĪ─Ń┐╔─▄Ģ■šf?░┘Č╚┘N░╔▓╗╩ŪČ╝ęčĮøø÷┴╦?
ĪĪĪĪ╔Žų▄┬Ā┼¾ėčĘųŽĒĄĮ▀@└’,╬ęā╚ą─ę▓ėąŅÉ╦ŲĄ─ę╔╗¾ĪŻ─├│÷╩ųÖC╦č┴╦Ž┬ĻPµIį~,šęĄĮŽ┬├µ▀@śėę╗Śl╠¹ūėĪŻ
ĪĪĪĪį┘Ę┼ę╗éĆ╬ę╦óĄĮĄ─╠¹ūė:
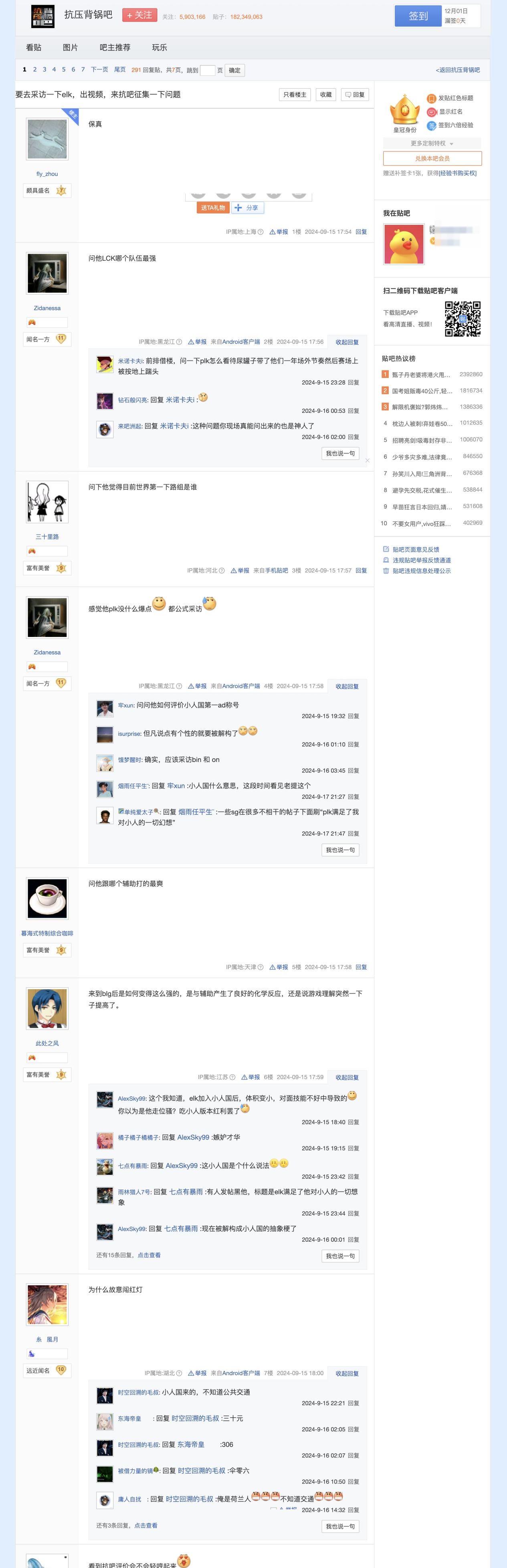
ĪĪĪĪ╬ęę╗Ž┬ūėŠ═├„░ū×ķ╩▓├┤ć°ā╚Ą─ Reddit ╩Ū░┘Č╚┘N░╔┴╦ĪŻ
ĪĪĪĪ┘N░╔╩Ū╠ņ╚╗Ą─ČÓ▌åī”įÆĖ±╩ĮĪŻ┤¾─Żą═ūŅ╚▒Ą─Š═╩ŪķLī”įÆĪŻķLī”įÆ▓╗╩Ūå¢ę╗Šõ┤ę╗Šõ,Č°╩Ūę╗éĆ╚╦ÆüéĆå¢Ņ},Ž┬├µ╩«ÄūéĆ╚╦ę╗Ų╔ŽüĒ,─Ńę╗Šõ╬ęę╗Šõ,╗źŽÓča│õĪó╗źŽÓæ╗Īó╗źŽÓūĘå¢,śŪīėę╗╠ņ─▄╔wĄĮā╔╚²░┘śŪĪŻ
ĪĪĪĪ▀@ĘNā╚╚▌,ī”┤¾─Żą═üĒšf,║åų▒Š═╩ŪīÜĪŻ╦³Ę¹║Ž─Żą═ė¢ŠÜĄ─Ė±╩Į:ų„Ņ} → ė^³c → ūĘå¢ → Ę┤±g → ╝Ü╗» → Ę┤Å═Į╗õhĪŻ
ĪĪĪĪį┘═∙╔Ņ└’┐┤,┘N░╔╔ŽėąĘŪ│ŻČÓĄ─┤╣ŅÉėæšōĪŻ
ĪĪĪĪ’@┐©Īóžł╔░Īó┐╝čąĪóæ¶═ŌĪóözė░Ų„▓─Īó│Ū╩ą……Äū║§╚╬║╬Š▀¾wĄ─å¢Ņ},Č╝─▄į┌┘N░╔šęĄĮī”æ¬Ą─░╔,▓óŪęų┴╔┘│┴ĄĒ┴╦╬Õ─ĻĪó╩«─Ļ╔§ų┴Ė³ķLĢrķgĪŻ
ĪĪĪĪę╗éĆų„Ņ}▓╗╩Ūę╗Ų¬╬─š┬,Č°╩Ū¤oöĄéĆå¢Ņ}Īó¤oöĄĘNå¢Ę©Īó¤oöĄéĆ╝Ü╣ØČčŲüĒĄ─ų¬ūRīėĪŻī”─Żą═üĒšf,╣┘ĘĮĮ╠│╠ų╗─▄ĖµįV╦³Ė┼─Ņ╩Ū╩▓├┤,Č°┘N░╔─▄ūī╦³ų¬Ą└į§├┤ė├Īóį§├┤▀xĪóį§├┤▒▄┐ė,▒│║¾Ą─įŁę“╩Ū╩▓├┤ĪŻ
ĪĪĪĪ▀@╩Ū═Ļ╚½▓╗═¼Ą─ā╔ĘNą┼Žó├▄Č╚ĪŻ
ĪĪĪĪ▀Ćėąę╗éĆ┐╔─▄▓╗╠½Ģ■ėą╚╦ö[į┌┼_├µ╔ŽšfĄ─:┘N░╔Ą─╗ž┤š▀,┤¾ČÓ╩Ū╗ņį┌─ŪéĆŅIė“║├ČÓ─ĻĄ─╔ŅČ╚═µ╝ęĪŻ╦¹éā┐╔─▄įÆ▓┌,Ą½Įø“ךµĄ─▓╗▓┌ĪŻ
ĪĪĪĪ▀@ĘN╚╦īæĄ─ā╚╚▌,┐┤ŲüĒ▓╗╚A¹É,Ą½╠žäeŠ▀¾wĪŻ▓╗Ģ■ĖµįV─Ń┤¾Ą└└Ē,ų╗Ģ■ĖµįV─Ń╬ę▓╚▀^╩▓├┤┐ėĪó╬ęį§├┤ĮŌøQĪó─Ńė÷ĄĮ▀@éĆŪķør╩«ėą░╦Š┼╩Ū▀@└’│÷┴╦å¢Ņ}ĪŻ
ĪĪĪĪ▀@ĘN¢|╬„,╩ŪŲĘ┼Ųūį╝║ė└▀hīæ▓╗│÷üĒĄ─,Ą½─Żą═╠žäeŽ▓ÜgĪŻ
ĪĪĪĪ«ö─Ń░č▀@Äū╝■╩┬Ę┼į┌ę╗Ų,Š═Ģ■░l¼Fę╗éĆ║▄ėąęŌ╦╝Ą─Ūķør:
ĪĪĪĪ┘N░╔ų«╦∙ęįųžą┬ūāĄ├ųžę¬,▓╗╩Ūę“×ķ╦³╗Ņ▄S,▓╗╩Ūę“×ķ╦³│▒,Č°╩Ūę“×ķ╦³╔Ē╔ŽĄ─įŁ╔·æBķLī”įÆĮYśŗ,äé║├╩Ū┤¾─Żą═ūŅ╚▒Ą─ĀIBĪŻ
ĪĪĪĪ─ŪąĪ╝tĢ°×ķ╩▓├┤▓╗ąą?
ĪĪĪĪ▓╗╩Ūę“×ķā╚╚▌▓╗║├,Č°╩Ū╦³Ą─▒Ē▀_ĘĮ╩Į▒╗ŲĮ┼_┴ĢæTĮyę╗Ą├╠½ÅžĄūĪŻ
ĪĪĪĪČ╠ŠõĪó╣╠Č©Ą─ŪķŠw╣ØūÓĪóęĢėX┼┼▓╝Īó─Ż░Õ╗»Ą─ķ_Ņ^,▀@╩ŪąĪ╝tĢ°Ą─ā×ä▌,ģsę▓ęŌ╬Čų°šZčį▒╗╠Ä└ĒĄ├╠½ŲĮ╗¼ĪŻė├æ¶Ą─¬qįźĪóĀÄšōĪó═Ų└Ē║═Ę┤Å═╦╝┐╝,▒╗ē║│╔ę╗ŚlŚlęĢėXėč║├Ą─╣Pėø,ą┼Žó╝Ü╣Ø£p╔┘┴╦,šZ┴xŠĆ╦„ę▓£\┴╦ĪŻ
ĪĪĪĪ─Żą═ŽļīWĄ─,╩Ū╚╦šµīŹĄ─╦╝┐╝▀^│╠,Č°▓╗╩Ūš¹└Ē▀^Ą─▒Ē▀_ĘĮ╩ĮĪŻ
ĪĪĪĪ▀@Š═╩Ū×ķ╩▓├┤Å─ GEO Ą─ĮŪČ╚┐┤,░┘Č╚┘N░╔Ė³ėą└¹ĪŻ
ĪĪĪĪ5
ĪĪĪĪ╚ń╣¹░č╔Ž├µ▀@ą®▀ē▌ŗ┬õĄĮīŹ▓┘╔Ž,╬ęūŅĮ³š¹└Ē┴╦ę╗Ę▌ūį╝║ūŅĮ³īW┴ĢĄ─╣Pėø,╣®┤¾╝ęģó┐╝:
ĪĪĪĪ1)░č«aŲĘĄ─║╦ą─ĻPµIį~üG▀M─Żą═,ūī╦³╔·│╔Äū╩«ĘN▓╗═¼å¢Ę©,į┘ĮY║Ž┐═Ę■┴─╠ņĪóõN╩█│ŻęŖå¢Ņ}Īó╔ńģ^╠ßå¢,š¹└Ēę╗Ę▌å¢Ņ}ŪÕå╬ĪŻ
ĪĪĪĪ2)ć·└@▀@ą®å¢Ņ}ū½īæ┐╔ė├Ą─┤░Ė,ų┴╔┘░³║¼:į§├┤ĮŌøQĪó×ķ╩▓├┤▀@śėĪóĄõą═ł÷Š░╩Ū╩▓├┤ĪŻ
ĪĪĪĪ3)Įo├┐éĆ║╦ą─ų„Ņ}īæę╗Ų¬─▄ųv═©ę“╣¹Ą─┤¾ĖÕ,Å─üĒ²ł╚ź├}ĪóįŁ└ĒĄĮ│ŻęŖš`ģ^,ę╗┤╬ąįųv═Ė,▒▄├Ō╦ķŲ¼╗»ĪŻ
ĪĪĪĪ4)░čė├æ¶Ą─▓╚┐ėĪóĘŁ▄ć║═ĮŌøQ▐kĘ©š¹└Ē│÷üĒ,īæ│╔å╬¬ÜĄ─ā╚╚▌,ūī─Żą═Ė³╚▌ęū▓ČūĮšµīŹ╝Ü╣ØĪŻ
ĪĪĪĪ5)░čā╚╚▌ĮYśŗš¹└ĒĄ├Ė³ęūūx:Č╠Č╬┬õĪó├„┤_Ą─▓Į¾EĪóąĪś╦Ņ},ūī─Żą═─▄š²┤_▓│╔ęŌ┴xå╬į¬ę²ė├ĪŻ
ĪĪĪĪ6)╠¶ 3 ĄĮ 5 éĆ┼c─Ń«aŲĘė├æ¶ųž»BČ╚ūŅĖ▀Ą─░┘Č╚┘N░╔ĪóReddit ╔ńģ^,ķLŲ┌į┌└’├µęįšµ╚╦ĘĮ╩Į╗źäėĪŻ
ĪĪĪĪ7)į┌▀@ą®░┘Č╚┘N░╔ĪóReddit └’,šJšµĄžĮŌøQå¢Ņ},▓╗Ū¾ŲĘ┼Ų╠ߥ├ČÓ,Ą½Ū¾╗ž┤ėąė├Īóėą╝Ü╣ØĪóėą┼ąöÓĪŻ
ĪĪĪĪ8)▀\ĀIę╗éĆķLŲ┌Ė³ą┬Ą─Į╠│╠,Å─╚ļķTĄĮ▀MļA,░č═¼ę╗éĆų„Ņ}Ą─ėæšōČ╝│┴ĄĒį┌śŪīė└’,ūī╦³ūį╚╗ķL│╔ČÓ▌åī”įÆśõĪŻ
ĪĪĪĪ9)č¹šłšµīŹė├æ¶ĘųŽĒūį╝║Ą─╩╣ė├ĮøÜv,▓╗ę¬ūī╦¹éāīæ│╔░Ė└²ĖÕ,Š═īæūį╝║į§├┤ė├Īó──└’▓╚┐ėĪóĮY╣¹į§├┤śėĪŻ
ĪĪĪĪ10)į┌▓╗═¼Ū■Ą└▒Ż│ųĮyę╗Ą─ŲĘ┼Ų├¹ĘQĪŻ
ĪĪĪĪ11)į┌ĻPµIā╚╚▌└’ūį╚╗ĮēČ©ŲĘ┼Ų├¹ + ╩╣ė├ł÷Š░,ūī─Żą═į┌ūźł÷Š░ĢrĒś╩ųėøūĪ─ŃĪŻ
ĪĪĪĪ12)Č©Ų┌į┌ų„┴„─Żą═└’╦č╦„Äū╩«éĆå¢Ę©,┐┤č█Ž┬─Żą═į§├┤├Ķ╩÷─ŃĪóėąø]ėą▒╗╠ߥĮĪó║═šl▓ó┴ą│÷¼FĪŻ
ĪĪĪĪ13)▀xō± 1 ĄĮ 2 éĆĻ楞,│ų└m▌ö│÷╔ŅČ╚ķL╬─,┐╔ęį╩Ūūį╝ę▓®┐═Īó╣½▒Ŗ╠¢,ę▓┐╔ęį╩Ū┤╣ų▒├Į¾wīŻÖ┌,ųž³cīæįŁ└ĒĮŌ╬÷ĪóąąśI┌ģä▌ĪóĘĮ░Ėī”▒╚ĪŻ
ĪĪĪĪŽŻ═¹ī”─Ńėąåó░lĪŻ

ĪĪĪĪąąśI┘YėŹĪóŲ¾śIäėæBĪóĘÕĢ■╗Ņäė┐╔░l╦═Ó]╝■ų┴news#citmt.cnŻ©░č#ōQ│╔@Ż®ĪŻ
║Żł¾╔·│╔ųą...

