
LMSYSÃĪyļžžöģÉČŦĮōīóÄĢÐÍÔuy―ðËĘĢŽĄ°šÚņRĄąYi-Large ĩĮí―ðŨÖËþžâ
ĄĄĄĄÉÏÖÜĢŽŌŧÃûé“im-also-a-good-gpt2-chatbot”ĩÄÉņÃØÄĢÐÍÍŧČŧŽFÉíīóÄĢÐÍļžžöChatbot ArenaĢŽÅÅÃûÖą―ÓģŽß^GPT-4-TurboĄĒGemini 1 .5 ProĄĒClaude 3 0pusĄĒLlama-3-70bĩČļũžŌøëHīóSĩÄŪžŌŧųŨųÄĢÐÍĄĢ
ĄĄĄĄëSšóOpenAI―Ōé_“im-also-a-good-gpt2-chatbot”ÉņÃØÃæž——ÕýĘĮGPT-4oĩÄyÔ°æąūĢŽOpenAI CEO Sam AltmanŌēÔÚGpt-4o°lēžšóÓHŨÔÞDĖûŌýÓà LMSYS arena ÃĪyĀÞÅ_ĩÄyÔ―YđûĄĢ

ĄĄĄĄÓÉé_·ÅŅÐūŋ―Mŋ LMSYS Org (Large Model Systems Organization)°lēžĩÄChatbot ArenaŌŅ―ģÉéOpenAIĄĒAnthropicĄĒGoogleĄĒMetaĩČøëHīóS“ý ŧĒķ·”ĩÄŪžtĀÞÅ_ĢŽŌÔŨîé_·ÅÅcŋÆWĩÄÔuy·―·ĻĢŽÔÚīóÄĢÐÍßMČëĩÚķþÄęÖŪëHé_·ÅČšąÍķÆąĄĢ
ĄĄĄĄrļôŌŧÖÜĢŽÔÚŨîÐÂļüÐÂĩÄÅÅÃûÖÐĢŽî“im-also-a-good-gpt2-chatbot”ĩÄšÚņRđĘĘÂÔŲīÎÉÏŅÝĢŽß@īÎÅÅÃûïwËŲÉÏqĩÄÄĢÐÍÕýĘĮÓÉÖÐøīóÄĢÐÍđŦËūÁãŌŧČfÎïĖá―ŧĩÄ“Yi-Large” Į§| Ēĩé]ÔīīóÄĢÐÍĄĢ
ĄĄĄĄÔÚ LMSYS ÃĪyļžžöŨîÐÂÅÅÃûÖÐĢŽÁãŌŧČfÎïĩÄŨîÐÂĮ§| ĒĩÄĢÐÍ Yi-Large ŋ°ņÅÅÃûĘĀ―įÄĢÐÍĩÚ7ĢŽÖÐøīóÄĢÐÍÖÐĩÚŌŧĢŽŌŅ―ģŽß^Llama-3-70BĄĒClaude 3 Sonnet;ÆäÖÐÎÄ·Ö°ņļüĘĮÅcGPT4o ēĒÁÐĘĀ―įĩÚŌŧĄĢ
ĄĄĄĄÁãŌŧČfÎïŌēÓÉīËģÉéÁËŋ°ņÉÏÎĻŌŧŌŧŨÔžŌÄĢÐÍßMČëÅÅÃûĮ°ĘŪĩÄÖÐøīóÄĢÐÍÆóIĄĢÔÚŋ°ņÉÏĢŽGPTÏĩÁÐÕžÁËĮ°10ĩÄ4ĢŽŌÔCÅÅÐōĢŽÁãŌŧČfÎï 01.AI HīÎÓÚ OpenAI, Google, AnthropicÖŪšóĢŽŌÔé_·Å―ðËĘÕýĘ―ßMôøëHížīóÄĢÐÍÆóIę IĄĢ
ĄĄĄĄÃĀørég2024Äę5ÔÂ20ČÕËĒÐÂĩÄ LMSYS Chatboat Arena ÃĪy―YđûĢŽíŨÔÖÁ―ņ·eĀÛģŽß^ 1170ČfĩÄČŦĮōÓÃôÕæÍķÆąĩĢš

ĄĄĄĄÖĩĩÃŌŧĖáĩÄĘĮĢŽéÁËĖáļß Chatbot Arena ēéÔĩÄÕûówŲ|ÁŋĢŽLMSYSßĘĐÁËÖØÍĩþhģýCÖÆĢŽēĒģöūßÁËČĨģýČßÓāēéÔšóĩÄ°ņÎĄĢß@ÐÂCÖÆÖžÔÚÏûģýß^ķČČßÓāĩÄÓÃôĖáĘūĢŽČįß^ķČÖØÍĩÄ“ÄãšÃ”ĄĢß@îČßÓāĖáĘūŋÉÄÜþÓ°íÅÅÐаņĩÄĘī_ÐÔĄĢLMSYSđŦé_ąíĘūĢŽČĨģýČßÓāēéÔšóĩÄ°ņÎĒÔÚšóĀmģÉéÄŽÕJ°ņÎĄĢ
ĄĄĄĄÔÚČĨģýČßÓāēéÔšóĩÄŋ°ņÖÐĢŽ Yi-LargeĩÄEloĩ÷ÖļüßMŌŧē―ĢŽÅcClaude 3 OpusĄĒGPT-4-0125-previewēĒÁÐĩÚËÄĄĢ
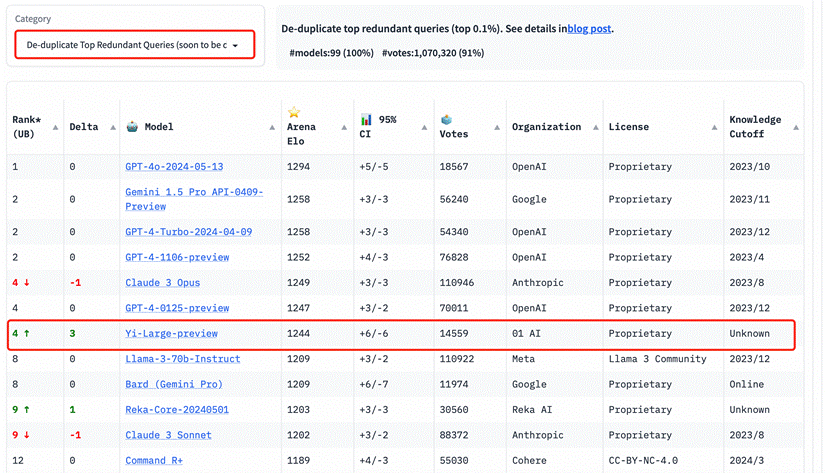
ĄĄĄĄLMSYS ÖÐÎÄ°ņĢšGPT-4o šÍ Yi-Large ēĒÁÐĩÚŌŧ
ĄĄĄĄÖĩĩÃøČËęPŨĒĩÄĘĮĢŽøČīóÄĢÐÍSÉĖÖÐĢŽÖĮŨVGLM4ĄĒ°ĒĀïQwen MaxĄĒQwen 1.5ĄĒÁãŌŧČfÎïYi-LargeĄĒYi-34B-chat īËīÎķžÓÐ ĒÅcÃĪyĢŽÔÚŋ°ņÖŪÍâĢŽLMSYS ĩÄÕZŅÔîeÉÏÐÂÔöÁËÓĒÕZĄĒÖÐÎÄĄĒ·ĻÎÄČý·NÕZŅÔÔuyĢŽé_ĘžŨĒÖØČŦĮōīóÄĢÐÍĩÄķāÓÐÔĄĢYi-LargeĩÄÖÐÎÄÕZŅÔ·Ö°ņÉÏ°ÎĩÃî^ŧIĢŽÅc OpenAI đŲÐûēÅŌŧÖÜĩÄĩØąíŨî GPT4o ēĒÁÐĩÚŌŧĢŽQwen-Max šÍ GLM-4 ÔÚÖÐÎÄ°ņÉÏŌēķžąíŽFēŧ·ēĄĢ

ĄĄĄĄ“ŨîýÄX” đŦé_ÔuyĢšYi-Large ÎŧūÓČŦĮōĩÚķþ
ĄĄĄĄÔÚ·ÖîeĩÄÅÅÐаņÖÐĢŽYi-LargeÍŽÓąíŽFÁÁŅÛĄĢūģĖÄÜÁĶĄĒéLĖáž°ŨîÐÂÍÆģöĩÄ “ÆDëyĖáĘūÔ~” ĩÄČýÔuyĘĮLMSYSËų―oģöĩÄáĶÐÔ°ņÎĢŽŌÔĢIÐÔÅcļßëyķČÖø·QĢŽŋÉ·QŨũīóÄĢÐÍ“ŨîýÄX”ĩÄđŦé_ÃĪyĄĢ
ĄĄĄĄÔÚūģĖÄÜÁĶ(Coding)ÅÅÐаņÉÏĢŽYi-Large ĩÄElo·ÖĩģŽß^Anthropic ŪžŌÆėÅÄĢÐÍ Claude 3 OpusĢŽHĩÍÓÚGPT-4oĢŽÅcGPT-4-TurboĄĒGPT-4ēĒÁÐĩÚķþĄĢ

ĄĄĄĄéLĖá(Longer Query)°ņÎÉÏĢŽYi-LargeÍŽÓÎŧÁÐČŦĮōĩÚķþĢŽÅcGPT-4-TurboĄĒGPT-4ĄĒClaude 3 OpusēĒÁÐĄĢ

ĄĄĄĄÆDëyĖáĘūÔ~(Hard Prompts)tĘĮLMSYSéÁËíŠÉį ^ŌŠĮóĢŽÓÚīËīÎÐÂÔöĩÄÅÅÐаņîeĄĢß@Ōŧîe°üšŽíŨÔ Arena ĩÄÓÃôĖá―ŧĩÄĖáĘūĢŽß@ÐĐĖáĘūt―ß^ĢéTÔOÓĢŽļüžÓÍësĄĒŌŠĮóļüļßĮŌļüžÓĀļņĄĢLMSYSÕJéĢŽß@îĖáĘūÄÜōyÔŨîÐÂÕZŅÔÄĢÐÍÃæÅRĖôðÐÔČÎÕrĩÄÐÔÄÜĄĢÔÚß@Ōŧ°ņÎÉÏĢŽYi-Large ĖĀíÆDëyĖáĘūĩÄÄÜÁĶŌēĩÃĩ―ÓĄŨCĢŽÅcGPT-4-TurboĄĒGPT-4ĄĒClaude 3 OpusēĒÁÐĩÚķþĄĢ

ĄĄĄĄLMSYS Chatbot ArenaĢššóbenchmarkrīúĩÄïLÏōË
ĄĄĄĄČįšÎéīóÄĢÐÍ―oģöŋÍÓ^đŦÕýĩÄÔuyŌŧÖąĘĮIČV·šęPŨĒĩÄÔî}ĄĢéÁËÔÚđĖķĻî}ėÖÐČĄĩÃŌŧ·ÝÁÁŅÛĩÄÔuy·ÖĩĢŽIČģöŽFÁËļũĘ―ļũÓĩÄ“ËĒ°ņ”·―·ĻĢšĒļũ·NļũÓĩÄÔuyŧųĘÓūžŊÖą―ÓŧėČëÄĢÐÍÓūžŊÖÐĄĒÓÃÎīĶýRĩÄÄĢÐÍļúŌŅ―ĶýRĩÄÄĢÐÍŨöĶąČĩČĩČĢŽĶLÔÁË―âīóÄĢÐÍÕæÄÜÁĶĩÄČËĢŽĩÄī_ģĘŽF“ąÕfžž”ĩÄŽFöĢŽļüŨīóÄĢÐÍĩÄÍķŲYČËÃþēŧÖøąąĄĢ
ĄĄĄĄÔÚ―ß^2023ÄęŌŧÏĩÁÐåeūCÍësĄĒyÏó ēÉúĩÄīóÄĢÐÍÔuyĀËģąÖŪšóĢŽI―įĶÓÚÔuyžŊĩÄĢIÐÔšÍŋÍÓ^ÐÔ―oÓčÁËļüļßĩÄÖØŌĄĢķøLMSYS Org °lēžĩÄChatbot Arena{―čÆäзfĩÄ“ļžžö”ÐÎĘ―ĄĒyÔFę ĩÄĀÖÐÔĢŽģÉéÄŋĮ°ČŦĮōI―įđŦÕJĩÄŧųĘËUĢŽßB OpenAI ÔÚ GPT-4o ÕýĘ―°lēžĮ°ĢŽķžÔÚ LMSYS ÉÏÄäÃûîA°lēžšÍîAyÔĄĢ
ĄĄĄĄÔÚšĢÍâīóSļßđÜÖÐĢŽēŧÖŧSam AltmanĢŽGoogle DeepMindĘŨÏŊŋÆWžŌJeff DeanŌēÔøŌýÓÃLMSYS Chatbot ArenaĩÄÅÅÃûĩþĢŽíŨôŨCBardŪaÆ·ĩÄÐÔÄÜĄĢ

ĄĄĄĄOpenAIĘžFę ģÉT Andrej KarpathyÉõÖÁđŦé_ąíĘūĢŽChatbot Arena is “awesome”ĄĢ
ĄĄĄĄŨÔÉíĩÄÆėÅÄĢÐÍ°lēžšóĩÚŌŧrégĖá―ŧ―oLMSYSĢŽß@ŌŧÐÐéąūÉíūÍÕđŽFÁËšĢÍâî^ēŋīóSĶÓÚChatbot ArenaĩÄOīóŨðÖØĄĢß@·ÝŨðÖØžČíŨÔÓÚLMSYSŨũéŅÐūŋ―MŋĩÄāÍþąģøĢŽŌēíŨÔÓÚÆäзfĩÄÅÅÃûCÖÆĄĢ
ĄĄĄĄđŦé_ŲYÁÏï@ĘūĢŽLMSYS Org ĘĮŌŧé_·ÅĩÄŅÐūŋ―MŋĢŽÓÉžÓÖÝīóWēŪŋËĀû·ÖÐĢĩÄWÉúšÍ―ĖĄĒžÓÖÝīóWĘĨĩØļį·ÖÐĢĄĒŋĻÄÍŧųÃ·ÂĄīóWšÏŨũÁĒĄĢëmČŧÖũŌŠČËTģöŨÔļßÐĢĢŽĩŦLMSYSĩÄŅÐūŋíÄŋ sĘŪ·ÖŲN―üŪaIĢŽËûēŧHŨÔžšé_°līóÕZŅÔÄĢÐÍĢŽßÏōIČÝģöķā·NĩþžŊ(ÆäÍÆģöĩÄMT-BenchŌŅĘĮÖļÁîŨņŅ·―ÏōĩÄāÍþÔuyžŊ)ĄĒÔuđĀđĪūßĢŽīËÍâßé_°l·ÖēžĘ―Ïĩ―yŌÔžÓËŲīóÄĢÐÍÓūšÍÍÆĀíĢŽĖáđĐūÉÏ live īóÄĢÐÍīōĀÞÅ_yÔËųÐčĩÄËãÁĶĄĢ
ĄĄĄĄÔÚÐÎĘ―ÉÏĢŽChatbot Arena―ččbÁËËŅËũŌýĮærīúĩÄMÏōĶąČÔuy˞·ĄĢËüĘŨÏČĒËųÓÐÉÏũÔuyĩÄ“ ĒŲ”ÄĢÐÍëSCÉÉÅäĶĢŽŌÔÄäÃûÄĢÐÍĩÄÐÎĘ―ģĘŽFÔÚÓÃôÃæĮ°ĄĢëSšóĖÕŲÕæÓÃôÝČëŨÔžšĩÄĖáĘūÔ~ĢŽÔÚēŧÖŠĩĀÄĢÐÍÐÍĖÃû·QĩÄĮ°ĖáÏÂĢŽÓÉÕæÓÃôĶÉÄĢÐÍŪaÆ·ĩÄŨũīð―oģöÔurĢŽÔÚÃĪyÆ―Å_ https://arena.lmsys.org/ ÉÏĢŽīóÄĢÐÍÉÉÏāąČĢŽÓÃôŨÔÖũÝČëĶīóÄĢÐÍĩÄĖáĢŽÄĢÐÍAĄĒÄĢÐÍB ÉČ·ÖeÉúģÉÉPKÄĢÐÍĩÄÕæ―YđûĢŽÓÃôÔÚ―YđûÏ·―ŨöģöÍķÆąËÄßxŌŧĢšAÄĢÐÍÝ^žŅĄĒBÄĢÐÍÝ^žŅĢŽÉÕßÆ―ĘÖĢŽŧōĘĮÉÕßķžēŧšÃĄĢĖá―ŧšóĢŽŋÉßMÐÐÏÂŌŧÝPKĄĢ

ĄĄĄĄÍĻß^ąŧIÕæÓÃôíßMÐÐūÉÏrÃĪyšÍÄäÃûÍķÆąĢŽChatbot ArenaŌŧ·―ÃæpÉŲÆŦŌĩÄÓ°íĢŽÁíŌŧ·―ÃæŌēŨîīóļÅÂĘąÜÃâŧųÓÚyÔžŊßMÐÐËĒ°ņĩÄŋÉÄÜÐÔĢŽŌÔīËÔöžÓŨî―KģÉŋĩÄŋÍÓ^ÐÔĄĢÔÚ―ß^ĮåÏīšÍÄäÃûŧŊĖĀíšóĢŽChatbot ArenaßþđŦé_ËųÓÐÓÃôÍķÆąĩþĄĢĩÃŌæÓÚ“ÕæÓÃôÃĪyÍķÆą”ß@ŌŧCÖÆĢŽChatbot Arenaąŧ·QéīóÄĢÐÍIČŨîÓÐÓÃôówļÐĩÄWÁÖÆĨŋËĄĢ
ĄĄĄĄÔÚĘÕžŊÕæÓÃôÍķÆąĩþÖŪšóĢŽLMSYS Chatbot ArenaßĘđÓÃEloÔu·ÖÏĩ―yíÁŋŧŊÄĢÐÍĩÄąíŽFĢŽßMŌŧē―ŧŊÔu·ÖCÖÆĢŽÁĶĮóđŦÆ―·īŠ ĒÅcÕßĩÄÁĶĄĢ
ĄĄĄĄEloÔu·ÖÏĩ―yĢŽĘĮŌŧíŧųÓÚ―yÓWÔĀíĩÄāÍþÐÔÔurówÏĩĢŽÓÉÐŲŅĀĀûŌáÃĀøÎïĀíWžŌArpad EloēĐĘŋÁĒĢŽÖžÔÚÁŋŧŊšÍÔuđĀļũîĶÞÄŧîÓĩÄļžžËŪÆ―ĄĢŨũéŪĮ°øëHđŦÕJĩÄļžžËŪÆ―ÔuđĀËĘĢŽEloĩČž·ÖÖÆķČÔÚøëHÏóÆåĄĒúÆåĄĒŨãĮōĄĒŧ@ĮōĄĒëŨÓļžžĩČß\ÓÖÐķž°l]ÖøÖÁęPÖØŌŠĩÄŨũÓÃĄĢ
ĄĄĄĄļüÍĻËŨĩØíÖvĢŽÔÚEloÔu·ÖÏĩ―yÖÐĢŽÃŋ ĒÅcÕßķžþŦ@ĩÃŧųĘÔu·ÖĄĢÃŋöąČŲ―YĘøšóĢŽ ĒÅcÕßĩÄÔu·ÖþŧųÓÚąČŲ―YđûßMÐÐÕ{ÕûĄĢÏĩ―yþļųþ ĒÅcÕßÔu·ÖíÓËãÆäÚAĩÃąČŲĩÄļÅÂĘĢŽŌŧĩĐĩÍ·ÖßxĘÖôĄļß·ÖßxĘÖĢŽÄĮÃīĩÍ·ÖßxĘÖūÍþŦ@ĩÃÝ^ķāĩÄ·ÖĩĢŽ·īÖŪtÝ^ÉŲĄĢÍĻß^ŌýČëEloÔu·ÖÏĩ―yĢŽLMSYS Chatbot ArenaÔÚŨîīóģĖķČÉÏąĢŨCÁËÅÅÃûĩÄŋÍÓ^đŦÕýĄĢ
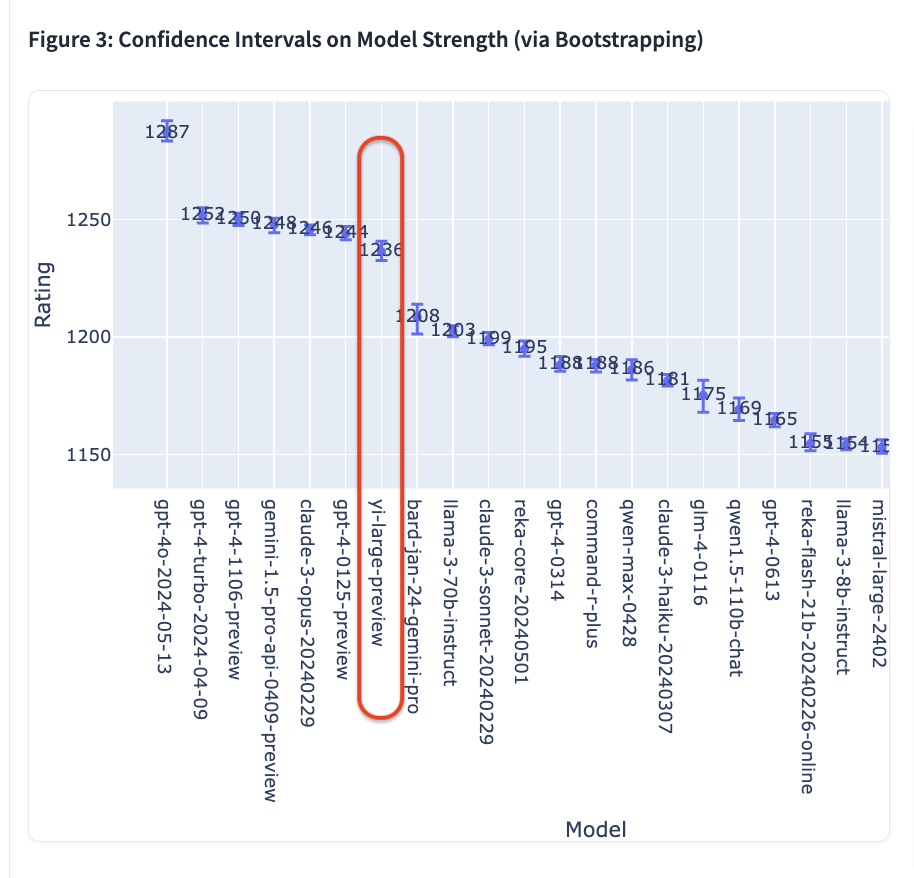
ĄĄĄĄChatbot ArenaĩÄÔuyß^ģĖšÉwÁËÄÓÃôÖą―Ó ĒÅcÍķÆąĩ―ÃĪyĢŽÔŲĩ―īóŌÄĢĩÄÍķÆąšÍÓBļüÐÂĩÄÔu·ÖCÖÆĩČķā·―ÃæĢŽß@ÐĐŌōËØđēÍŽŨũÓÃĢŽī_ąĢÁËÔuyĩÄŋÍÓ^ÐÔĄĒāÍþÐÔšÍĢIÐÔĄĢšÁoŌÉĢŽß@ÓĩÄÔuy·―Ę―ÄÜōļüĘī_ĩØ·īÓģģöīóÄĢÐÍÔÚëHŠÓÃÖÐĩÄąíŽFĢŽéÐÐIĖáđĐÁËŌŧŋÉŋŋĩÄ ĒŋžËĘĄĢ
ĄĄĄĄYi-Large ŌÔÐĄēŦīóūoŨ·øëHĩÚŌŧę IĢŽĩĮíøČīóÄĢÐÍÃĪy
ĄĄĄĄīËīÎChatbot ArenađēÓÐ44ŋîÄĢÐÍ ĒŲĢŽžČ°üšŽÁËížâé_ÔīÄĢÐÍLlama3-70BĢŽŌē°üšŽÁËļũžŌīóSĩÄé]ÔīÄĢÐÍĄĢ

ĄĄĄĄŌÔŨîÐÂđŦēžĩÄEloÔu·ÖíŋīĢŽGPT-4oŌÔ1287·ÖļßūÓ°ņĘŨĢŽGPT-4-TurboĄĒGemini 1 5 ProĄĒClaude 3 0pusĄĒYi-LargeĩČÄĢÐÍtŌÔ1240ŨóÓŌĩÄÔu·ÖÎŧūÓĩÚķþĖÝę ;ÆäšóĩÄBard (Gemini Pro)ĄĒLlama-3-70b-InstructĄĒClaude 3 sonnetĩÄģÉŋtāŅÂĘ―ÏÂŧŽÖÁ1200·ÖŨóÓŌĄĢ
ĄĄĄĄÖĩĩÃŌŧĖáĩÄĘĮĢŽÅÅÃûĮ°6ĩÄÄĢÐÍ·ÖewŲÓÚšĢÍâūÞî^ OpenAIĄĒGoogleĄĒAnthropicĢŽÁãŌŧČfÎïÎŧÁÐČŦĮōĩÚËÄCĢŽĮŌGPT-4ĄĒGemini 1.5 ProĩČÄĢÐÍūųéČf|žeģŽīó ĒĩŌÄĢĩÄÆėÅÄĢÐÍĢŽÆäËûÄĢÐÍŌēķžÔÚīóŨĮ§| ĒĩžeĄĢYi-Large “ŌÔÐĄēŦīó” ŌÔHHĮ§| ĒĩÁŋžūoŨ·ÆäšóĢŽ 5ÔÂ13ČÕŌŧ―°lēžąã_ÉÏĘĀ―įÅÅÃûĩÚÆßīóÄĢÐÍĢŽÅcšĢÍâīóSĩÄÆėÅÄĢÐÍĖÓÚÍŽŌŧĖÝę ĄĢÔÚ LMSYS Chatbot Arena ―ØÖÁ5ÔÂ21ČÕĩÄŋ°ņÉÏĢŽ°ĒĀï°Í°ÍĩÄ Qwen-Max īóÄĢÐÍ Elo·Öĩé1186ĢŽÅÅÃûĩÚ12;ÖĮŨVAI ĩÄGLM-4 īóÄĢÐÍ Elo·Öĩé 1175ĢŽÅÅÃûĩÚ15ĄĢ
ĄĄĄĄÔÚŪĮ°īóÄĢÐÍē―ČëÉĖIŠÓÃĩÄĀËģąÖÐĢŽÄĢÐÍĩÄëHÐÔÄÜØ―ÐčÍĻß^ūßówŠÓÃöū°ĩÄĀļņŋžōĢŽŌÔŨCÃũÆäÕæÕýĩÄrÖĩšÍÁĶĄĢß^ČĨÄĮ·NHŌŠĮóąíÃæđâõrĩÄ“ŨũÐãĘ―”Ôuy·―Ę―ŌŅēŧÔŲūßÓÐëHŌâÁxĄĢéÁËīŲßMÕûīóÄĢÐÍÐÐIĩÄ―Ąŋĩ°lÕđĢŽÕûÐÐIąØíŨ·ĮóŌŧ·NļüéŋÍÓ^ĄĒđŦÕýĮŌāÍþĩÄÔuđĀówÏĩĄĢ
ĄĄĄĄÔÚß@ÓĩÄąģū°ÏÂĢŽŌŧČįChatbot Arenaß@ÓÄÜōĖáđĐÕæÓÃô·īðĄĒēÉÓÃÃĪyCÖÆŌÔąÜÃâēŲŋv―YđûĄĒēĒĮŌÄÜōģÖĀmļüÐÂÔu·ÖówÏĩĩÄÔuyÆ―Å_ĢŽï@ĩÃÓČéÖØŌŠĄĢËüēŧHÄÜōéÄĢÐÍĖáđĐđŦÕýĩÄÔuđĀĢŽßÄÜōÍĻß^īóŌÄĢĩÄÓÃô ĒÅcĢŽī_ąĢÔuy―YđûĩÄÕæÐÔšÍāÍþÐÔĄĢ
ĄĄĄĄoÕĘĮģöÓÚŨÔÉíÄĢÐÍÄÜÁĶĩüīúĩÄŋž]ĢŽßĘĮÁĒŨãÓÚéLÆÚŋÚąŪĩÄŌ―ĮĢŽīóÄĢÐÍSÉĖŠŪ·eO ĒÅcĩ―ÏņChatbot Arenaß@ÓĩÄāÍþÔuyÆ―Å_ÖÐĢŽÍĻß^ëHĩÄÓÃô·īðšÍĢIĩÄÔuyCÖÆíŨCÃũÆäŪaÆ·ĩÄļ ÁĶĄĢ
ĄĄĄĄß@ēŧHÓÐÖúÓÚĖáÉýSÉĖŨÔÉíĩÄÆ·ÅÆÐÎÏóšÍĘÐöĩØÎŧĢŽŌēÓÐÖúÓÚÍÆÓÕûÐÐIĩÄ―Ąŋĩ°lÕđĢŽīŲßMžžÐgКÍŪaÆ·ŧŊĄĢÏā·īĢŽÄĮÐĐßxņŨũÐãĘ―ĩÄÔuy·―Ę―ĢŽšöŌÕæŠÓÃЧđûĩÄSÉĖĢŽÄĢÐÍÄÜÁĶÅcĘÐöÐčĮóÖŪégĩÄøÏþÔ―°lÃũï@ĢŽŨî―KĒëyŌÔÔÚžĪÁŌĩÄĘÐöļ ÖÐÁĒŨãĄĢ

ĄĄĄĄÐÐIŲYÓĄĒÆóIÓBĄĒI―įÓ^ücĄĒ·åþŧîÓŋÉ°lËÍā]žþÖÁnews#citmt.cnĢĻ°Ņ#QģÉ@ĢĐĄĢ
šĢóÉúģÉÖÐ...

